01 引言
我们已经分了两节介绍了XPath的基础用法、进阶技巧以及特殊神技,但都是基于浏览器的测试的,并没有实际运用的场景。本节我们将通过实际的案例应用Xpath技术。
02 项目背景
企业中,为了分析竞品,就可能会抓取竞品的数据进行拆解,然后更好的完善自己的产品并超越竞品;我们也会经常遇到通过省市区作为筛选条件的组件,这些基础的也需要从国家统计局官网爬取数据等等。
但是,不是所有的数据多可以爬取。如果恶意爬取隐私数据等就可能会触犯法律。这也是IT圈调侃的面向监狱编程。有可能是正人畜无害的码着代码,帽子叔叔就请你喝茶了。
在Robots协议允许范围内抓取公开数据,并尊重网站反爬虫措施(如验证码限制),通常不违法。抓取已公开的非敏感数据用于科研、分析等非商业用途,且在数据使用中不侵犯他人权益(如隐私权、著作权)时,可认定为合法。
所以编程有风险,爬虫需谨慎!
我们以公开信息以当当网的图书列表为例,获取【汪汪队立大功】的列表数据。
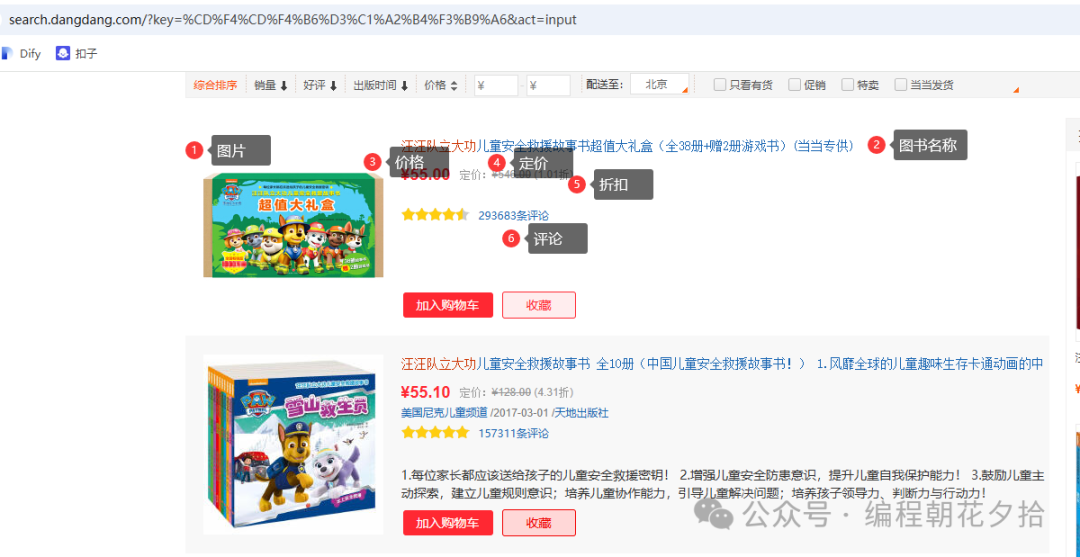
爬取数据:
-
图书的图片链接
-
图书名称
-
图书价格
-
图书定价
-
图书折扣
-
图书评论
03 爬虫编写
编写爬虫我们需要因为第三方插件,支持XPath语法
3.1 Maven依赖引入
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>2.5.3</version>
</dependency>
JDK 本身支持XPath,但是只能解析xml,对Html支持并不友好,所以选择了第三方插件。
3.2 页面分析
整体分析
浏览器打开F12
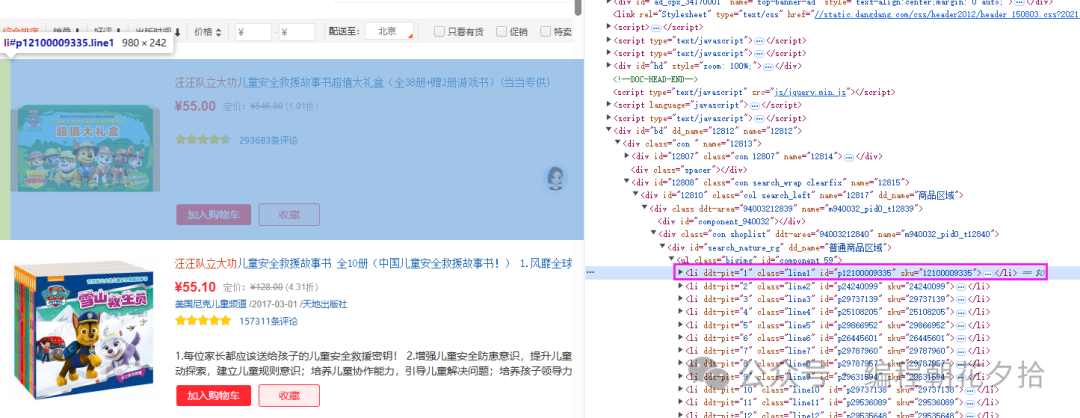
可以看出每一个li 标签就是一个商品,我们只需要取出所有的li 就可以获取到当前列表的所有的数据了。
Xpath语法:
//ul[@id='component_59']/li
详细拆解元素
想要获取目标数据,只需要处理li中的子标签即可。
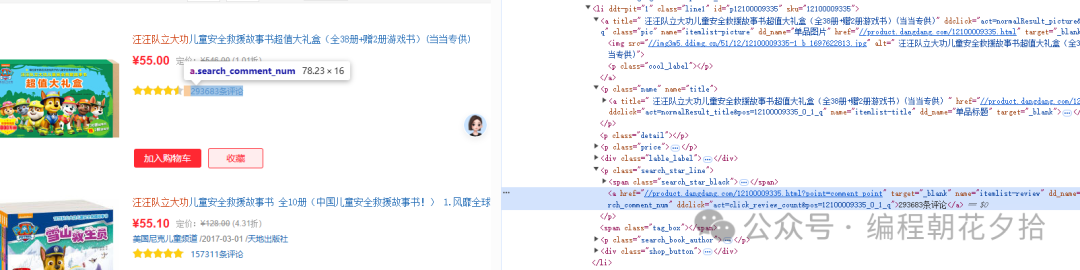
Xpath语法:
# 图片地址
//ul[@id='component_59']/li/a/img/@src
# 图书名称
//ul[@id='component_59']/li/p[@class='name']/a/@title
# 图书价格
//ul[@id='component_59']/li/p[@class='price']/span[1]/text()
# 图书定价
//ul[@id='component_59']/li/p[@class='price']/span[@class='search_pre_price']/text()
# 图书折扣
//ul[@id='component_59']/li/p[@class='price']/span[@class='search_discount']/text()
# 图书评论
//ul[@id='component_59']/li/p[@class='search_star_line']/a/text()
3.3 代码实战
@Test
voidtest01() {
StringmiUrl="https://search.dangdang.com/?key=%CD%F4%CD%F4%B6%D3%C1%A2%B4%F3%B9%A6&act=input";
JXDocumentjxDocument= JXDocument.createByUrl(miUrl);
// 获取商品列表
List<JXNode> jxNodes = jxDocument.selN("//ul[@id='component_59']/li");
intcount=1;
for (JXNode jxNode : jxNodes) {
System.out.println("第【"+ count +"】本书:");
System.out.println(" 图书图片地址:" + xpathThenGet(jxNode, "/a/img/@src"));
System.out.println(" 图书名称:" + xpathThenGet(jxNode, "/p[@class='name']/a/@title"));
System.out.println(" 图书当前价格:" + xpathThenGet(jxNode, "/p[@class='price']/span[1]/text()"));
System.out.println(" 图书定价:" + xpathThenGet(jxNode, "/p[@class='price']/span[@class='search_pre_price']/text()"));
System.out.println(" 图书折扣:" + xpathThenGet(jxNode, "/p[@class='price']/span[@class='search_discount']/text()"));
System.out.println(" 图书评论:" + xpathThenGet(jxNode, "/p[@class='search_star_line']/a/text()"));
System.out.println("-----------------图书分割线-----------------------");
count++;
}
}
private String xpathThenGet(JXNode jxNode, String xpathExpression) {
return Optional.ofNullable(jxNode.selOne(xpathExpression)).map(JXNode::asString).orElse("暂无");
}
代码解析:
代码中分了两步处理,第一步先获取所有的li元素,第二步通过遍历li元素,获取每一个li元素里面的具体内容。
3.4 运行结果
总共获取到60本图书的信息:
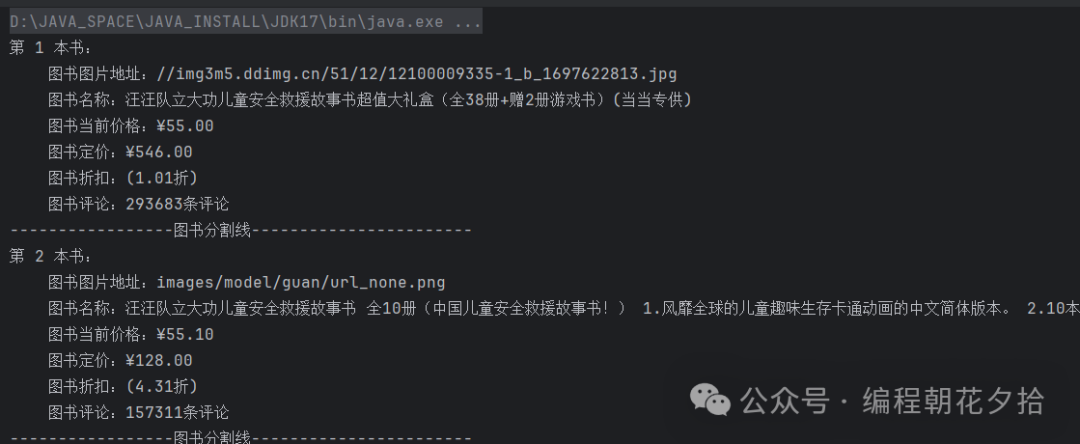
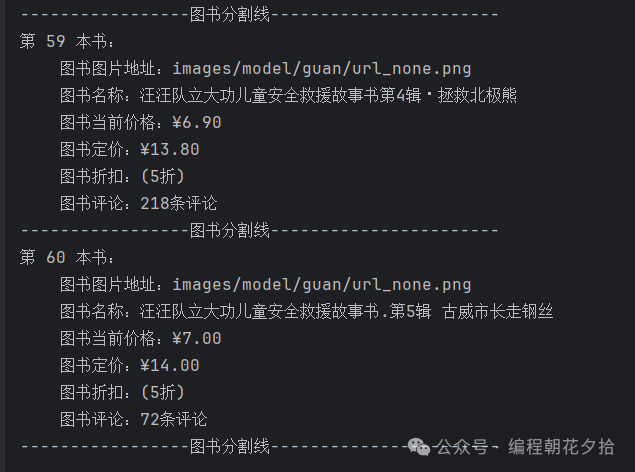
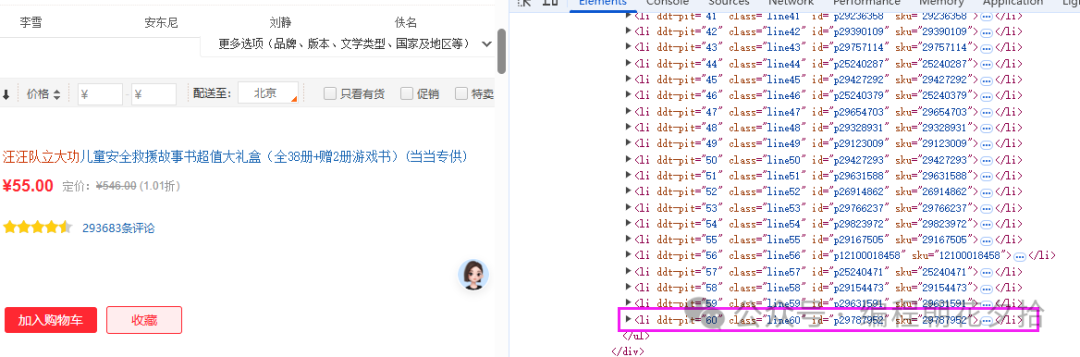
从页面元素来看,确实就是60本书
04 小结
本节只是介绍了一个简单的案例,并通过所学完整一个小项目。如果只是处理一些简单的页面是可以直接使用的。但是好的爬虫需要考虑爬取的性能、可移植性、环境、安全性等方面,感兴趣的可以考虑考虑。