1.宏观上分析java代码的执行流程

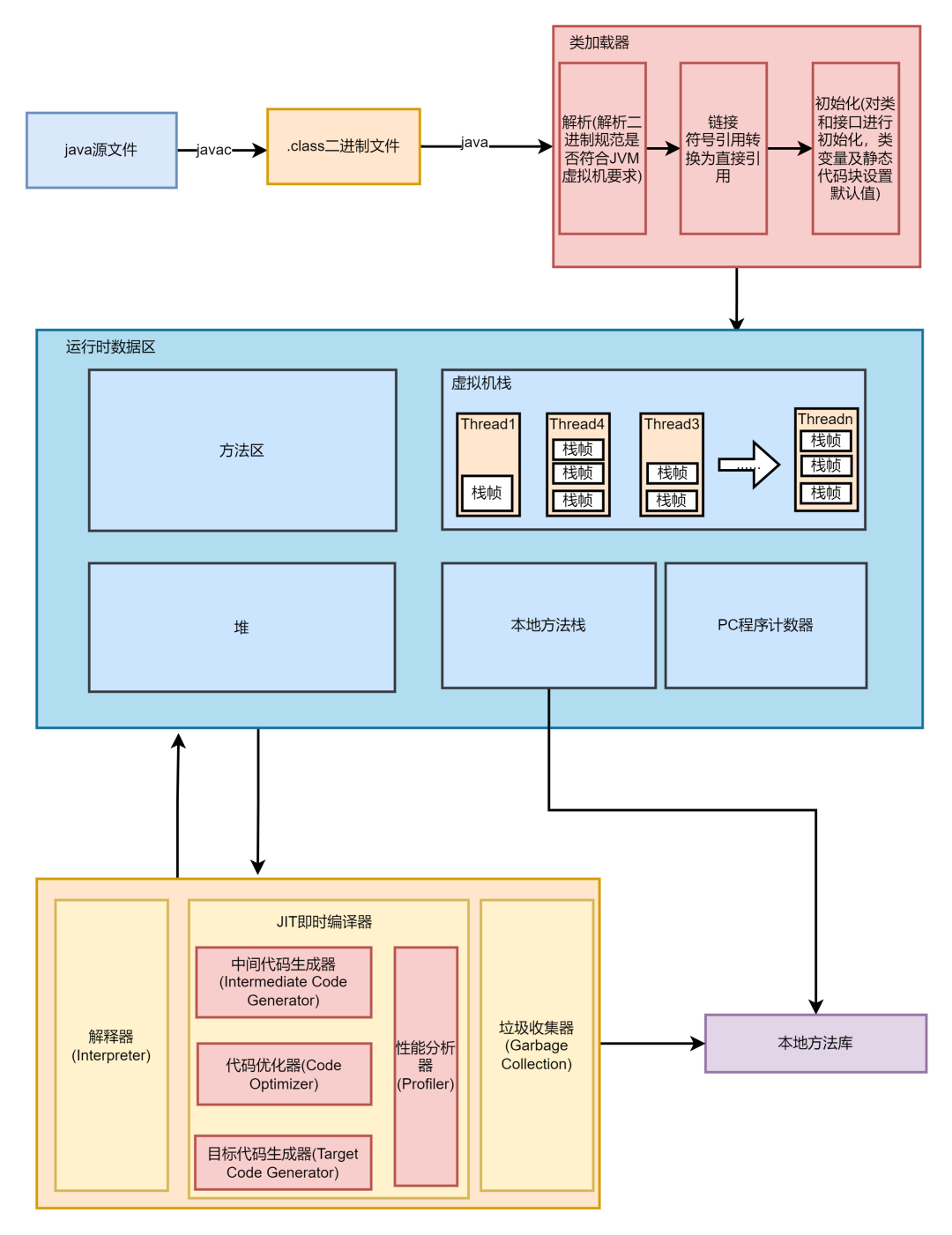
编译阶段:代码编译是从.java源文件通过编译器转换形成.calss字节码文件的过程(javac编译器)
执行阶段:.class字节码文件会通过JVM中的解释器,翻译成特定机器上的机器码,并执行对应的指令。
问题:这两个阶段会操作内存吗?什么时候操作内存?
1、 编译阶段仅仅只是将源文件代码转换为对应的字节码,该过程不会执行指令,因此不会操作内存。
2、 执行阶段会将字节码文件解释为机器码(解释执行),并执行指令(编译执行),因此该过程会频繁操作内存
2.编译阶段执行流程
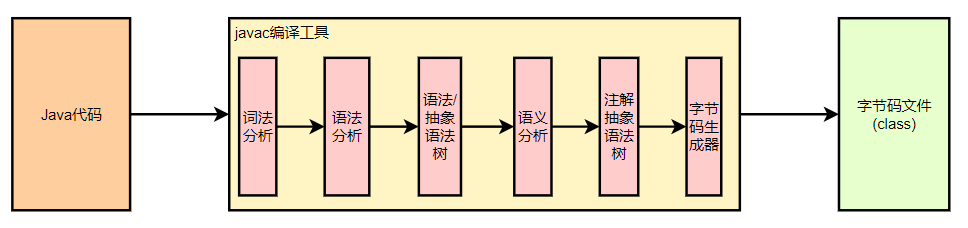
编译阶段仅仅只是把源文件转换成对应的字节码,那我们可以知道,Java代码首先一定会经过javac编译器编译一次
Javac编译java源文件转换为字节码文件的过程如下图所示:
2.1 javac执行步骤分析
javac的组件如下图
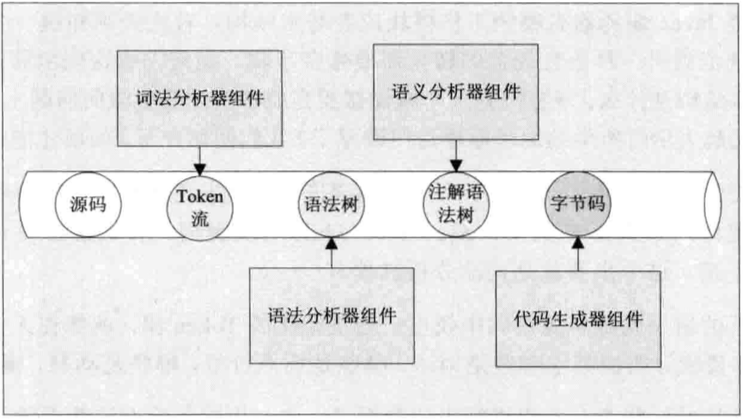
源代码执行流程如下图
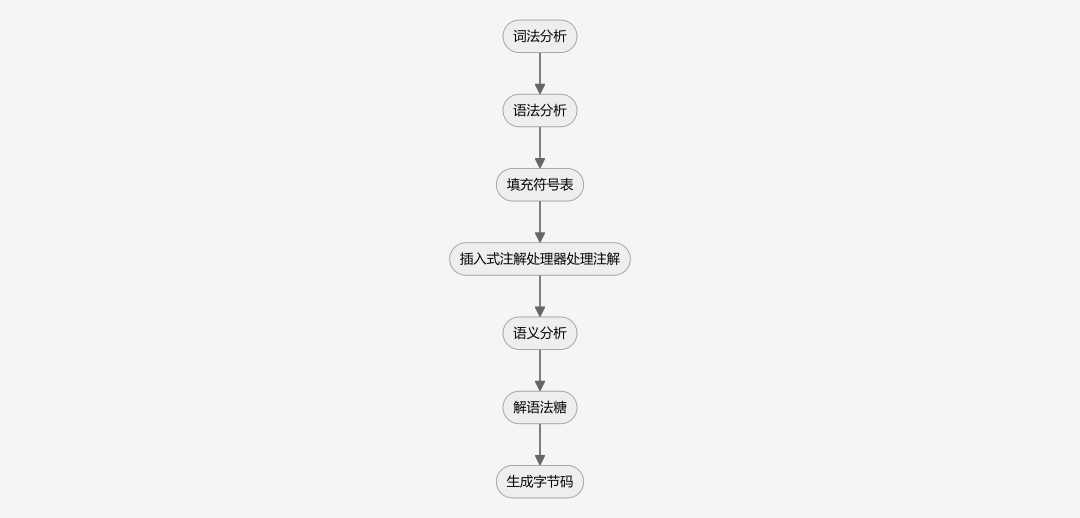
词法分析:把源代码中的单个字符(各关键字、变量等)转为Token序列,token是编译过程的最小单元,ScannerFactory和ParserFactory用于生成Scanner和JavacParser对象,JavacParser用于规定哪些词符合java语言规范,Scanner用于逐步读取和归类不同的词法操作,解析出Token序列,Names用于存储和表示解析后的词法
语法分析:将Token流构造成为抽象语法树,语法树的每一个节点都代表代码中的一个语法结构(包、类型、接口、修饰符等)
填充符号表:符号表是一组符号地址和符号信息构成的表格,符号表会填充每个抽象语法树和package-info.java的顶级节点,生成一个待处理列表
插入式注解处理器处理注解:注解处理器可以增删改抽象语法树中的任意元素,因此每当注解处理器对语法树进行修改时,都会从词法分析重新开始执行,直到注解处理器不再修改语法树为止,每一次的循环过程称为一次Round
语义分析:对语法树结构上正确的源程序进行上下文有关的审查,分为标注检查和数据及控制流分析两个步骤,参数不变性由编译器在编译期保障
- 标注检查:检查的内容包括变量使用前是否被声明,变量与赋值的数据类型是否能匹配等,以及常量折叠:int i=1+2;,会被折叠成字面量3
- 数据及控制分析:数据及控制分析是对程序上下文逻辑更进一步的验证,例如:检查变量是否初始化,方法的每个执行分支是否都有返回值,是否所有的异常都被正确处理等,这个阶段并不会对变量赋值
解语法糖:
- 语法糖的定义:在计算机语言中(如java)添加某种语法,这种语法对整个语法的功能并没有影响,但是更方便程序员使用,增加程序的可读性,减少程序出错的机会
- 解语法糖就是将java中的语法(语法糖)还原回基础语法结构,例如:泛型、变长参数、自动装箱/拆箱、遍历循环、内部类、断言等JVM不支持的语法结构还原回最基础的语法结构,这个过程叫解语法糖
生成字节码:将前面步骤生成的语法树、符号表等信息转化为字节码,然后写入磁盘.class文件
ClassFile {
u4 magic; //Class 文件的标志
u2 minor_version;//Class 的小版本号
u2 major_version;//Class 的大版本号
u2 constant_pool_count;//常量池的数量
cp_info constant_pool[constant_pool_count-1];//常量池
u2 access_flags;//Class 的访问标记
u2 this_class;//当前类
u2 super_class;//父类
u2 interfaces_count;//接口
u2 interfaces[interfaces_count];//一个类可以实现多个接口
u2 fields_count;//Class 文件的字段属性
field_info fields[fields_count];//一个类可以有多个字段
u2 methods_count;//Class 文件的方法数量
method_info methods[methods_count];//一个类可以有个多个方法
u2 attributes_count;//此类的属性表中的属性数
attribute_info attributes[attributes_count];//属性表集合
}
3.执行阶段执行流程
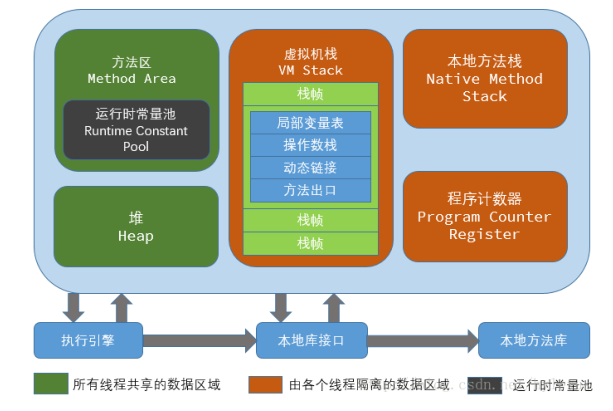
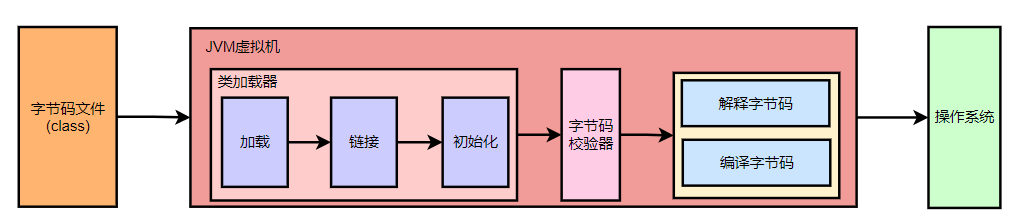
Java文件通过编译后生成的class字节码文件,会加载到JVM中执行,JVM执行过程主要分为加载和执行两个阶段
- 加载:会将Java文件通过javac执行后的ClassFile通过类加载器(ClassLoader)加载到内存区域,类加载器会对ClassFile进行加载、链接、初始化(也就是进行解析)
- 执行:将初始化后的数据根据类型的不同分别存放在不同的内存区域,并通过执行引擎运行字节码指令对栈进行操作(执行引擎运行的字节码指令只会操作当前栈帧(指令流--基于栈的指令集架构))
执行阶段,Java虚拟机对class字节码文件进行的操作如下图所示:
具体操作参考下图:
类的定义分为三类保存
- initCode:保存需要初始化执行的实例变量和非static修饰的块
- clinitCode:保存需要初始化执行的类变量和static修饰的块
- methodDefs:保存方法定义符号
把initCode中的定义插入到实例构造器init()中
- 如果程序中定义有构造函数,它在解析的语法分析阶段就会被重命名为init()
- 如果程序中定义没有构造函数,则实例构造器init()就是作为默认构造函数,在填充符号表时被添加
- 如果程序中定义的构造函数没有显式调用super()或this(),会添加super()的父类构造函数调用
- 如果程序中定义没有构造函数,则填充符号表时添加的默认构造函数会自带super()
把clinitCode中的定义插入到类构造器clinit()中
- init()是在每次实例化对象时执行
- clinit()是在类加载器加载该类时执行
4. 扩展内容-沙箱安全机制
- Java安全模型的核心是Java沙箱(sandbox)
- 什么是沙箱:沙箱是一个限制程序运行的环境。沙箱机制就是将Java代码限定在虚拟机特定的运行范围中,并且严格限制代码对本地系统资源访问
- 作用:保证对代码的有效隔离,限制系统资源的访问、防止对本地系统造成破坏--系统资源包括:CPU、内存、文件系统、网络等。
- Java安全模型:在Java中将执行程序分为本地代码和远程代码两种,本地代码默认视为可信任的,而远程代码则被看作是不受信任的。对于授信的本地代码可以访问一切本地资源(例如:创建文件夹、修改文件内容等),而对于非授信的远程代码在早期的Java实现中,安全依赖于沙箱机制(1.0版本完全隔离)。
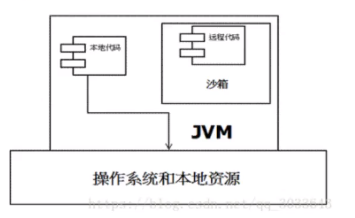
- 1.1版本针对安全机制做了改进,增加了安全策略,允许用户指定对本地资源的访问权限
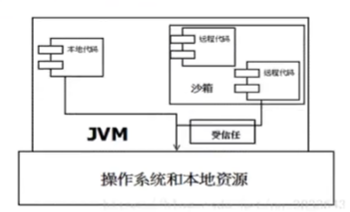
- 1.2版本再次改进安全机制,增加了代码签名,不论是本地代码或是远程代码,都会 按照用户的安全策略设定 ,由类加载器加载到虚拟机中 权限不同的运行空间 ,来实现差异化代码的执行权限控制
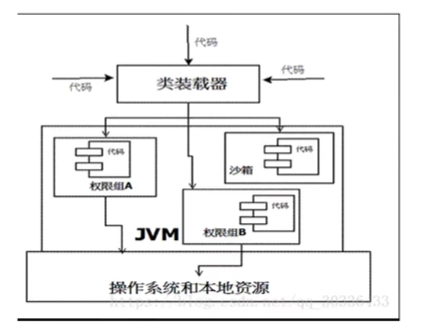
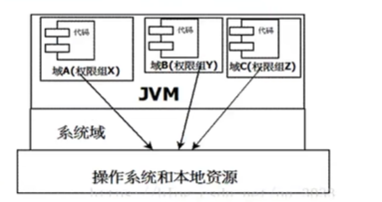
- 当前的是最新的安全机制,引入了域(Domain)的概念。虚拟机会把所有代码加载到不同的系统域或应用域, 系统域 部分专门负责与关键资源进行交互,而各个 应用域 部分则通过系统域的部分代理来对各种需要的资源进行访问。虚拟机中不同的受保护域(Protected Domain),对应不一样的权限(Premission)。 存在于不同的域中的类文件就具有了当前域的全部权限
- 沙箱的基本组件:
- Java.security下的类和扩展包下的类,允许用户为自己的应用增加新的安全特性,包括:
- 安全提供者
消息摘要
数字签名
加密
鉴别
- 是核心API和操作系统之间的主要接口,实现权限控制,比存取控制器优先级高。
- 存取控制器可以控制核心API对操作系统的存取权限,而这个控制的策略设定,可以由用户指定
- 它防止恶意代码干涉善意的代码(双亲委派机制)
它守护了被信任的类库边界
它将代码归入保护域,确定了代码可以进行哪些操作
- 字节码校验器(bytecode verifier):确保Java类文件遵循Java语言规范。这样可以帮助Java程序实现内存保护,但并不是所有的类文件都会经过字节码校验,比如核心类。
类装载器(ClassLoader):其中类装载器在三个方面对Java沙箱起作用
虚拟机为不同的类加载器载入的类提供了不同的命名空间,命名空间由一系列唯一的名称组成,每个被装载的类将有一个名字,这个命名空间是由Java虚拟机为每一个类装载器维护的,它们互相之间甚至不可见。
存取控制器
安全管理器
安全软件包