上周经历了一次k8s集群的重大故障,
有多重大呢?整个k8s集群的node节点全部重启了。
故障原因呢?我当然是不会说的。
但是我想分享一下在处理这个故障过程中积累的一点知识
先说现象
在k8s集群重启完成,各个kube-system的服务都正常了之后,业务pod开始重启。
在这个时候我们发现业务pod的恢复特别慢。
进一步追查日志,是因为我们使用了istio。
而istiod服务此时还没有启动成功,这就导致了Istio 使用 ValidatingAdmissionWebhooks 验证 Istio 配置的时候验证失败,阻挡了业务pod的启动。
自然的,我们去追查istio的pod启动问题。结果发现,不管我们修改istio的repicas数量还是删除重建istio pod,都不能创建出isto的pod。
排查和解决
看到这个现象,自然会想到是pod调度出问题了。
我们指导controller manager是控制容器的数量符合配置的repicas数量,scheduler是给等待调度的pod计算出合适的node节点,
在这个时候看到的是pod都没有创建出来,都还没到调度。
所以将重点对准了controller manager
在api-server中看到了Rate Limited相关的日志
OpenAPI AggregationController: action for item v1beta1.metrics.k8s.io: Rate Limited Requeue.
...
loading OpenAPI spec for "v1beta1.metrics.k8s.io" failed with: failed to retrieve openAPI spec, http error: ResponseCode: 503, Body: service unavailable
, Header: map[Content-Type:[text/plain; charset=utf-8] X-Content-Type-Options:[nosniff]]
故推测是大量业务pod同时重启,导致controller-manager忙不过来了。
回想起controller-manager似乎有一些关于并发的配置参数,
查询官方文档
kube-controller-manager | Kubernetes
修改了这三个参数

image-20240828192755354
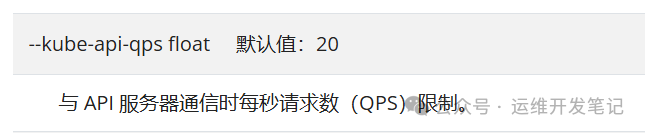
image-20240828192820462

image-20240828192836498
controller-manager是静态pod,直接修改master节点上的资源文件即可。
修改文件 /etc/kubernetes/manifests/kube-controller-manager.yaml
添加配置参数
--concurrent-replicaset-syncs=20
--kube-api-qps=50
--kube-api-burst=100
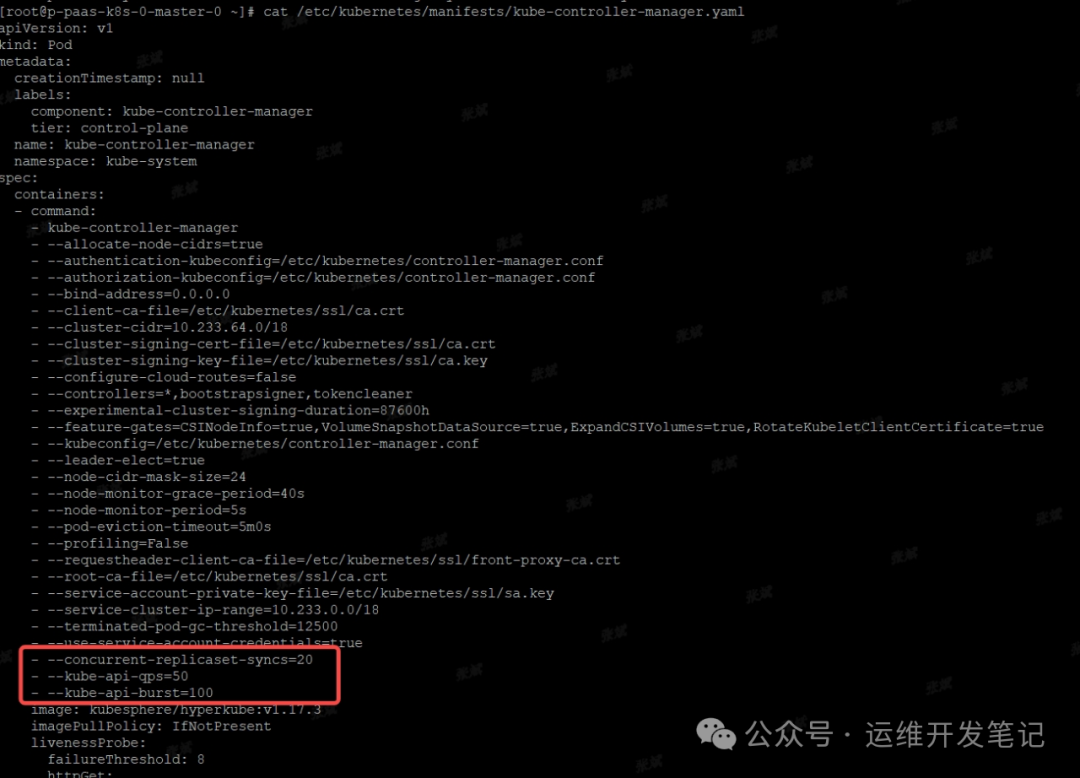
image-20240828154950220
重启之后,istiod的pod确实很快创建了出来。业务pod也得到了快速的恢复。
其实加这三个参数是有碰运气的成分在里面,我并不确定如果不修改这三个参数,只是重启controller-manager故障是不是也能解决。
但是在cpu比较富裕的情况下,将并发参数调大是合理的。