索引的结构
每一个索引在物理存储上对应一颗B+树
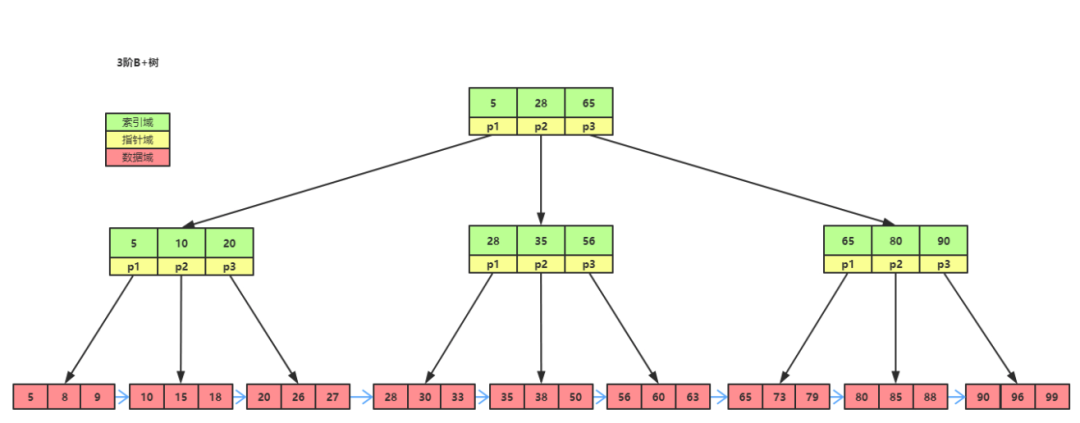 B+树
B+树
索引分为主键索引和非主键索引
主键索引也称为聚簇索引,树的叶子结点存储整行数据。
非主键索引的叶子结点存储主键的值。
因此基于非主键索引的查询需要检索两棵B+树,先检索非主键索引查到对应的主键,再根据主键查到数据,这个过程称为“回表”
也不是所有情况都要回表,假如只查询索引字段和主键,在索引所在的B+树中就能查到,这时就不需要回表。这种情况叫索引覆盖。
索引的建立原则
1、 用到什么查询条件提前分析好,用到什么就建什么索引,不要过度添加,增加索引会导致变更数据的额外开销
2、 最左前缀匹配原则:建立联合索引后(a,b,c),当查询条件使用了联合索引的最左部分字段(a)、(a,b)、(a,b,c),都可以用到该索引
3、 建立联合索引时需注意字段的声明顺序,最常用的放最前面,区分度高的放前面
执行计划
通过explain sql可以看到相应SQL的执行计划,执行计划的字段说明如下
| 字段 | 说明 | 优化意义 |
|---|---|---|
| id | 查询的序列号 | 相同id按顺序执行,不同id从大到小执行 |
| select_type | 查询类型: SIMPLE(简单查询) PRIMARY(外层查询) SUBQUERY(子查询)等 | 识别复杂查询结构 |
| table | 访问的表名或别名 | 确认查询涉及的表 |
| partitions | 匹配的分区 | 确认分区裁剪是否生效 |
| type | 访问类型 | 关键指标,下面详细解释 |
| possible_keys | 可能使用的索引列表 | 检查是否有合适的索引候选 |
| key | 实际使用的索引 | 确认索引是否被正确使用 |
| key_len | 使用的索引长度(字节数) | 判断是否使用了索引的全部部分 |
| ref | 索引与哪些列或常量比较 | 了解索引使用方式 |
| rows | 预估需要检查的行数 | 行数过大可能有问题 |
| filtered | 表条件过滤的百分比(0-100) | 值越小表示过滤效果越好 |
| Extra | 额外执行信息 | 重要优化提示 |
id
id相同时执行顺序由上至下;id不同时,如果是子查询,id 的序号会递增,id值越大优先级越高,越先被执行
type
执行计划类型,对查询性能影响很大,由好到坏排序:
- system:表中只有一行数据
- const:通过主键或唯一索引定位单条记录
- eq_ref:多表关联时,关联条件使用主键或唯一索引
- ref:使用非唯一索引查找
- range:索引范围扫描(BETWEEN, IN, >, <等)
- index:全索引扫描
- all:全表扫描
一般至少要优化到range级别,最好能到ref以上
ref
| 分类 | 说明 | 优化建议 | 示例 |
|---|---|---|---|
| const | 与常量值比较 | 理想状态,无需优化 | WHERE id = 5 → ref: const |
| 列名 | 多表关联的列比较 | 确保关联字段都有索引 | ON a.id=b.id → ref: db.b.id |
| func | 使用函数处理索引列 | 重写查询避免函数操作 | YEAR(date_col)=2023 → ref: func |
| NULL | 未使用索引比较 | 考虑添加合适索引 | WHERE text_col='x' (无索引) |
extra
| Extra值 | 含义描述 | 优化建议 |
|---|---|---|
| Using index | 使用覆盖索引(查询列全在索引中) | 理想状态,无需优化 |
| Using where | 存储引擎检索行后,服务器层再通过WHERE条件过滤 | 检查是否可改为索引条件过滤 |
| Using temporary | 使用临时表处理查询(常见于GROUP BY/ORDER BY/DISTINCT) | 优化SQL或为分组/排序字段添加索引 |
| Using filesort | 使用文件排序(非索引排序) | 为排序字段创建索引 |
| Using join buffer | 使用连接缓冲(Block Nested Loop) | 优化关联查询或调整 join_buffer_size |
| Impossible WHERE | WHERE条件始终为假(如 WHERE 1=0 ) | 检查查询逻辑 |
| Select tables optimized away | 通过索引优化已无需访问表(如聚合函数MIN/MAX使用索引) | 理想状态 |
| Distinct | 优化DISTINCT操作 | 检查是否可以去除DISTINCT |
| Start temporary/End temporary | 表示子查询使用了临时表(常见于IN/EXISTS优化) | 考虑重写子查询 |
| Range checked for each record | 对每行重新评估索引范围(当关联列类型不匹配时) | 检查表关联字段类型是否一致 |
| Full scan on NULL key | 子查询中的NULL值导致全表扫描 | 避免在索引列上使用NULL条件 |
| const row not found | 使用唯一索引但未找到匹配行 | 检查查询条件 |
| unique row not found | 使用唯一索引关联但未找到匹配行 | 检查关联条件 |
| Using intersect/union/sort_union | 使用索引合并优化(index_merge) | 考虑创建复合索引替代多个单列索引 |
一些不走索引的情况
1、 索引列参与计算
2、 索引列使用了函数
3、 使用了隐式的类型转换
4、 使用 like '%xxx' 后缀匹配
5、 字符串与数字直接比较
6、 避免使用 or ,除非条件中的所有字段都建立了索引。
7、 条件中带有 != 或 <>
8、 联合索引的使用不符合最左前缀匹配
9、 使用了is null或is not null
不知不觉连更了19篇了...我可能需要暂停歇一段时间,身体扛不住