哈喽,大家好,我是BiggerBoy!
之前分享了一篇百万数据秒级导出!Java后台高效Excel导出方案全解析,有朋友们希望能提供一下源码便于学习,最近比较忙,今天它终于来了,抽时间整理了一下发出来。
效果:
环境:本地windows11 + Java8
数据库:MySQL
JVM:堆内存总大小4g,年轻代2g
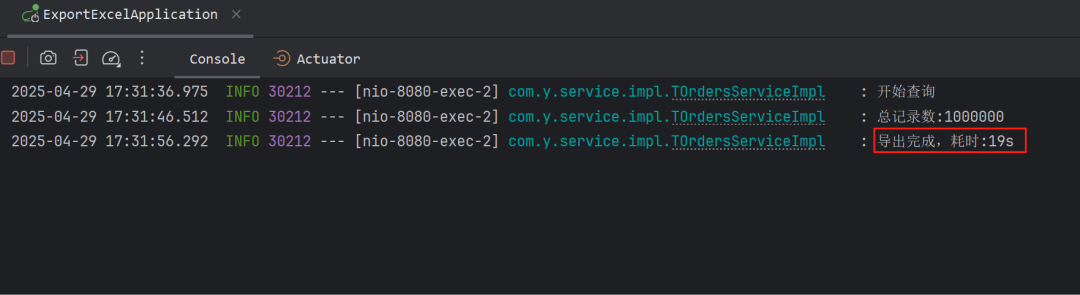
本地测试结果如下:
控制台输出:导出100万数据19秒
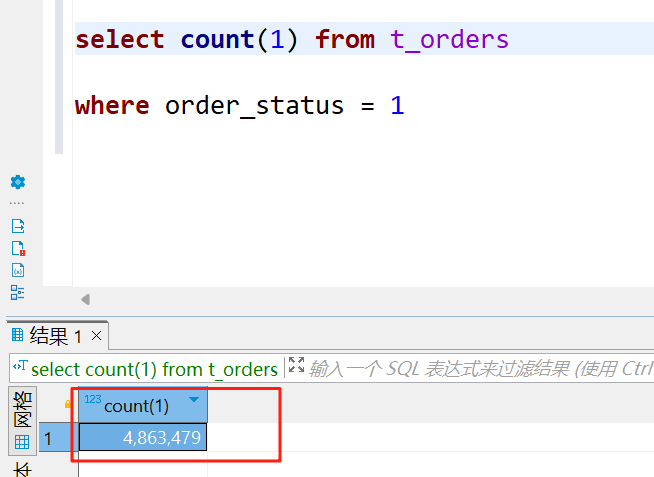
全表数据量:486万+
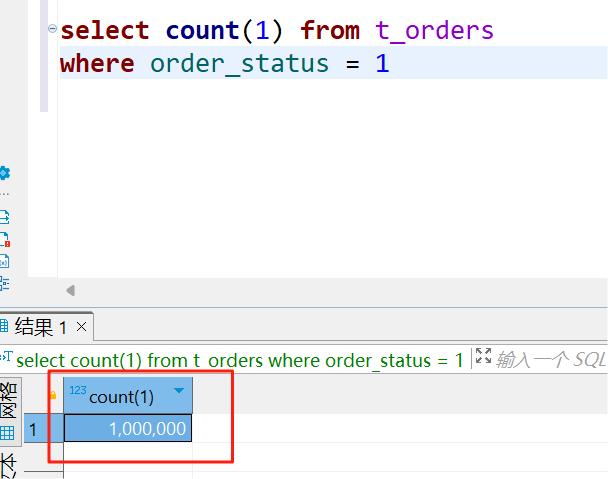
本次导出数据量:100万整
导出文件大小:50MB
导出业务流程:
开始
分页查询数据
根据总量和指定的每个文件数据量计算文件个数
根据文件数据量和指定的每个sheet数据量计算sheet个数
开启多线程写入文件
关键代码:
这个方法包含了导出的主流程:
1.获取数据
2.指定导出文件名等相关信息
3.使用Easyexcel导出文件
public void exportOrdersToExcel(int type) throws IOException {
long timeMillis= System.currentTimeMillis();
//1.获取数据
List<TOrders> data = getOrders(type);
//2.指定导出文件名、每个文件数据量,每个文件sheet数
ExportConfig<TOrders> exportConfig = new ExportConfig<>();
exportConfig.setData(data);
exportConfig.setFileDataSize(100000);
exportConfig.setFileName("t-order-");
exportConfig.setSheetDataSize(10000);
exportConfig.setHeaderClass(TOrders.class);
//3.使用easyexcel导出
ExportService<TOrders> exportService = new ExportService<>();
exportService.exportToExcel(exportConfig, executor);
logger.info("导出完成,耗时:{}s", (System.currentTimeMillis() - timeMillis) / 1000);
}
获取数据:
因为数据量比较大,牵涉到深分页的问题,所以下面代码获取数据采用的游标方式,即根据lastId + limit分批查询,比传统分页查询性能好很多。
深分页问题和优化方案可以参考之前的这篇[MySQL 深分页性能优化终极指南:告别慢查询的 5 大方案][MySQL _ 5]
public List<TOrders> getByLastId(Integer lastId, Integer size) {
List<TOrders> tOrdersAll = new ArrayList<>();
List<TOrders> tOrders = tOrdersMapper.selectByLastId(lastId, size);
while (CollectionUtils.isNotEmpty(tOrders)) {
tOrdersAll.addAll(tOrders);
lastId = tOrders.get(tOrders.size() - 1).getOrderId();
if (lastId == null || lastId == 0) {
break;
}
tOrders = tOrdersMapper.selectByLastId(lastId, size);
}
return tOrdersAll;
}
使用EasyExcel导出:
exportService.exportToExcel的源码:
-
调用exportConfig.getExportConfig()方法,获取分割后的文件配置
-
分割后,使用exportConfigList,采用多线程并行写入多个文件
-
使用线程池执行写入操作
-
获取sheet数据,使用EasyExcel写入
• 写入完成后,countDownLatch减1
-
等待所有线程执行完成
public voidexportToExcel(ExportConfig<T> exportConfig, Executor executor) {
//1.调用exportConfig.getExportConfig()方法,获取分割后的文件配置
List<ExportConfig<T>> exportConfigList = exportConfig.getExportConfig();
//2.分割后,使用exportConfigList,采用多线程并行写入多个文件
CountDownLatchcountDownLatch=newCountDownLatch(exportConfigList.size());
for (inti=0; i < exportConfigList.size(); i++) {
ExportConfig<T> config = exportConfigList.get(i);
intfinalI= i;
//3.使用线程池执行写入操作
executor.execute(() -> {
StringpathName="C:\\export\\" + config.getFileName() + "-" + System.currentTimeMillis() + "-" + finalI + ".xlsx";
try (ExcelWriterexcelWriter= EasyExcel.write(pathName, config.getHeaderClass()).build()) {
//4.获取sheet数据,使用EasyExcel写入
config.getSheetData().forEach((sheetConfig, data) -> {
WriteSheetwriteSheet= EasyExcel.writerSheet(sheetConfig.getSheetNo(), sheetConfig.getSheetName()).build();
excelWriter.write(data, writeSheet);
});
} catch (Exception e) {
thrownewRuntimeException(e);
} finally {
//5.写入完成后,countDownLatch减1
countDownLatch.countDown();
}
});
}
try {
//6.等待所有线程执行完成
countDownLatch.await();
} catch (InterruptedException e) {
thrownewRuntimeException(e);
}
}
文件分割:exportConfig.getExportConfig()
分割文件,根据数据总数和指定的每个文件数据量进行分割。
public List<ExportConfig<T>> getExportConfig() {
if (CollectionUtils.isNotEmpty(data) && fileDataSize != null && data.size() > fileDataSize) {
List<ExportConfig<T>> exportConfigs = Lists.newArrayList();
//分成多个文件
List<List<T>> fileDataPartition = Lists.partition(data, fileDataSize);
for (List<T> fileData : fileDataPartition) {
ExportConfig<T> exportConfig = newExportConfig<>(this); // 使用拷贝构造函数
exportConfig.setData(fileData); // 重置数据
processSheetData(fileData, exportConfig);
exportConfigs.add(exportConfig);
}
return exportConfigs;
} else {
processSheetData(data, this);
return Lists.newArrayList(this);
}
}
最后启动项目,调用导出,查看导出结果: