大家好,今天我们讨论的问题是Spark的优化。
这个问题无论是在实际工作还是面试中都是经常被问到的问题,从Spark1.x到Spark3.x版本,Spark的性能本身有了大幅提升。
Spark性能优化一般会涉及资源配置、代码设计、数据倾斜处理等等,我们一般的思路如下:
1、 基础配置上,我们要考虑资源分配,并行度配置、序列化配置;
2、 数据特性上,小文件、数据倾斜、Shuffle等;
3、 高级特性上,我们还会推荐使用AQE、CBO,采用更优的算子等。
在上面思路的基础上,配合Spark UI与事件日志工具,逐步验证调优效果。
以上是开发维度上的探讨,今天我们要讨论的是基于Native SQL向量化引擎上的优化。
什么是向量化引擎
我们在很早的文章中分享过关于向量化引擎的介绍,简单的说:
向量化引擎是一种数据处理架构,通过批量处理列数据(而非逐行处理)来提升计算效率。
其核心思想是利用现代CPU的SIMD(单指令多数据)指令集(如AVX、SSE),将相同类型的列数据打包成向量,一次性处理多个数据元素,从而减少指令开销和内存访问次数。
是近几年来Native SQL向量化计算引擎层出不穷,出现多种优秀框架。
例如大家熟悉的数据库产品ClickHouse、Doris,本身就通过深度利用CPU向量化指令和列存架构,达到了极高的性能。
此外,Meta公司以Library的方式发布的Velox,也经过了业界广泛验证和实践。
那么Spark是怎么做的呢?这就是我们今天要分享的内容:Gluten。
Spark + Gluten
Gluten是专为Spark SQL设计的高性能向量化执行引擎,通过替换Spark原生的Shuffle和计算引擎,显著提升查询性能。
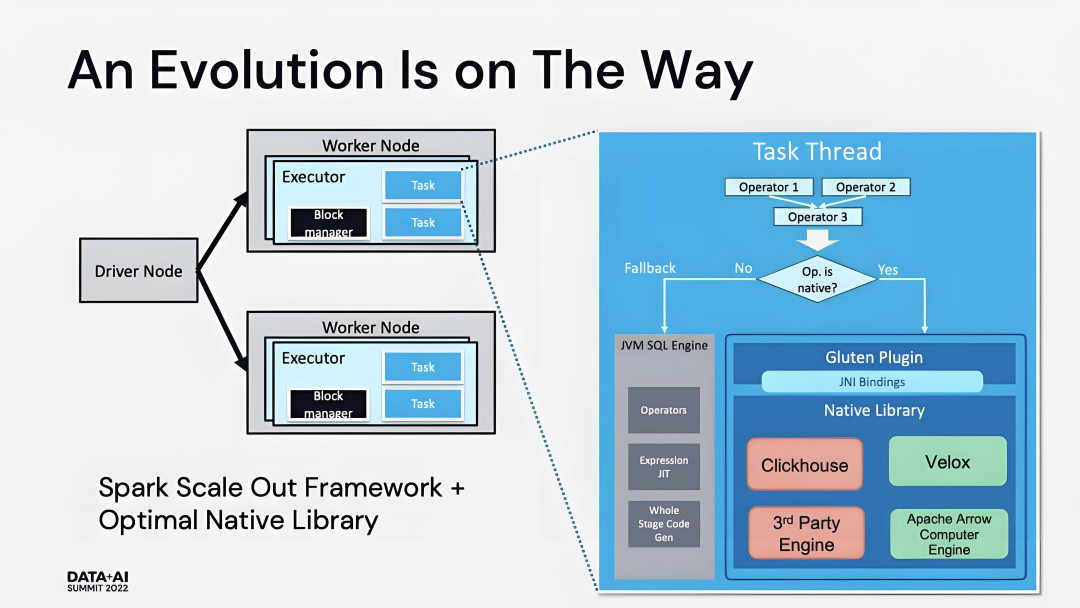
在Spark+Gluten的架构中,整个框架仍然使用Spark原有的Master/Worker方式去运行。
Spark在执行任务时,会做一个判断如果Operator或Expression是Native引擎支持的情况,就会交由Gluten,然后通过JNI接口去调用Native向量化引擎做计算,从而提升性能。
如果存在未支持的Operator或者Expression的情况,就会做fallback,让它回到Spark原生的JVM引擎去执行。
Gluten是什么?
Gluten项目由Intel和Kyligence于2021年合作共建,旨在通过开源社区推进Native Spark实现,为Spark扩展向量化执行(Vectorized Execution)能力,进一步提升引擎查询性能和CPU利用率。
Gluten整体设计思想沿用Spark执行框架,基于新增GlutenPlugin和加载Session Extensions实现自定义扩展。
整体架构
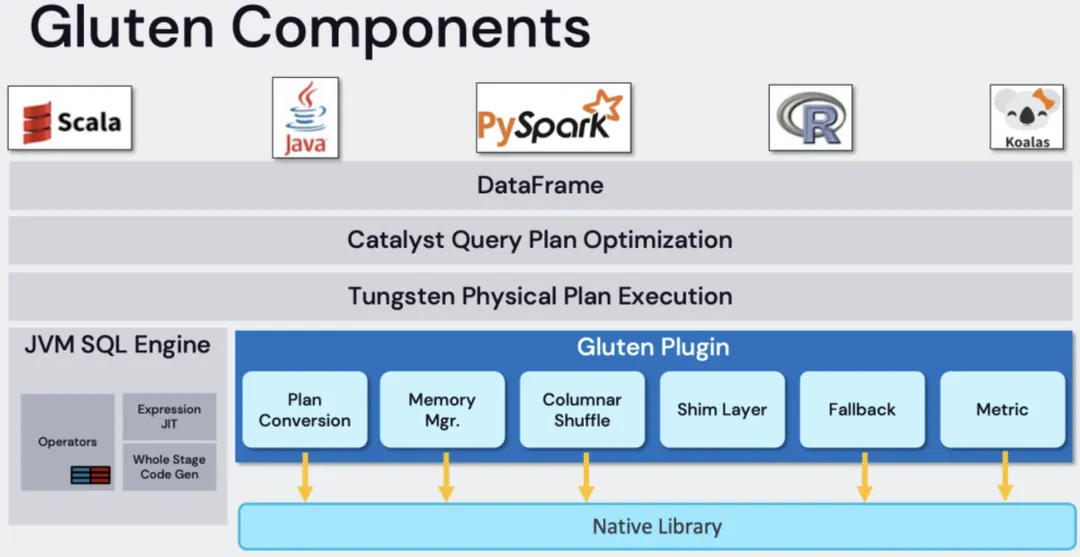
Gluten Plugin在向量化执行中处于「承上启下」位置,承上对接Spark物理计划,启下对接原生Native执行引擎。Gluten Plugin组件如图所示包括:
1、 Plan Conversion: Gluten最核心组件,基于规则将SparkPlan转换为GlutenPlan;
2、 Memory Manager: 实现Native Engine内存统一由Spark管理;
3、 Columnar Shuffle: Gluten重要特性,通过列式数据结构优化 Spark Shuffle实现,避免了在 Shuffle 过程中频繁的数据行转列和列转行操作,从而显著提升Shuffle I/O性能;
4、 Shim Layer: 支持多版本Spark;
5、 Fallback: 执行容错和支持回退JVM执行;
6、 Metric: 指标上报 Spark Metrics System。
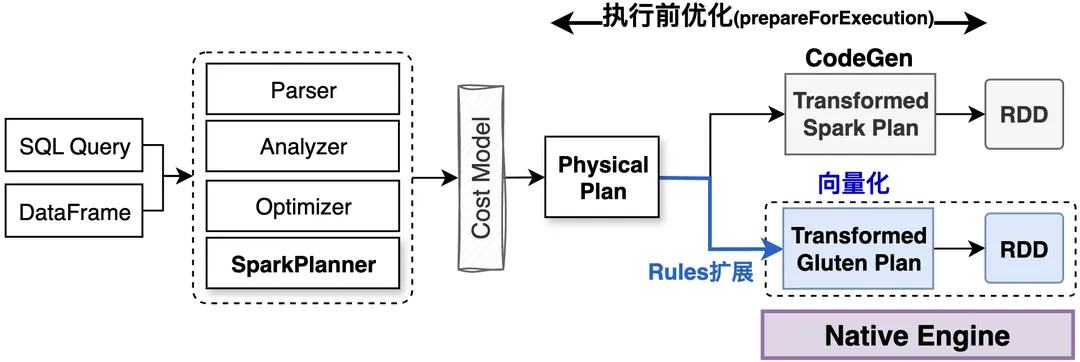
Spark Driver处理查询请求的基本流程如下图所示:
1、 基于Spark Catalyst框架进行SQL解析和逻辑计划优化
2、 基于SparkPlanner进行物理计划优化
3、 优化后的物理计划SparkPlan基于规则进行处理并转换成RDD对象。
Spark底层执行基于火山模型实现,需要对每个算子进行迭代计算。
为提升执行效率,从Spark2.0开始,社区开始引入全阶段代码生成(Whole-stage Code Generation)优化。基于CodeGen 将子计划树压缩为一段可执行代码,避免子计划树节点的逐个计算,大幅减少虚函数调用,显著提升查询性能。
从Spark3.0开始,社区支持自适应查询执行(Adaptive Query Execution,AQE) ,在DAG Stage执行过程中,基于上一个Stage的真实执行统计信息,重新生成更优的执行计划,动态优化下一个Stage的执行逻辑。

Gluten实现向量化计算的主要变更如下所示,在QueryExecution执行前优化过程中,通过注入规则对物理计划进行扩展处理,转为Gluten物理计划,使用向量化执行模式替换已有的JVM + CodeGen的执行模式。在Task执行阶段,基于Gluten RDD,通过JNI调用Native引擎(默认Velox)实现向量化执行。
提升效果
截止目前,支持的operator包含Scan、Filter、Project、HashAggregate。Join支持BroadcastHashJoin、ShuffledHashJoin。
通过各种测试显示,最终可以给Spark带来了2到3倍甚至更多性能上的提升。