探索 DataX 数据同步工具,提供高效的 MySQL 和 HDFS 数据同步方法。本文详细介绍了 DataX 的安装、配置和使用技巧,帮助您轻松实现跨库同步和增量同步。无论是全量同步还是增量同步,DataX 都能快速准确完成任务。点击了解更多 DataX 3.0 的核心架构与操作技巧。
前言
咱公司有个项目,数据量大得吓人,差不多得五千万条。问题来了,报表那块数据不准,而且业务库和报表库跨库操作,SQL 同步根本行不通。开始时想通过 mysqldump 或者存储方式搞定,结果尝试之后发现根本不行,完全不靠谱:
mysqldump: 备份和同步都得耗费不少时间,而且备份的过程中,还得担心数据出错(换句话说,同步也就等于没同步)。
存储方式: 效率真的是太低了,数据量少还能凑合点,我们搞的时候,3小时才同步2000条数据……
后来上网查了查,终于发现了 DataX 这个神器,速度快得不要不要的,而且同步数据的量和准确性也几乎没问题。
一、DataX 简介
DataX 就是阿里云 DataWorks 数据集成的开源版本,它主要用来做数据间的离线同步。这个工具支持多种不同的数据库间同步,像 MySQL、Oracle、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源都可以搞定。
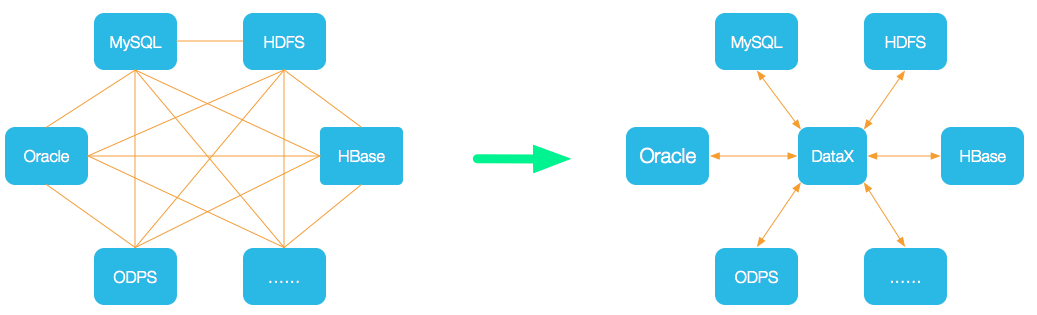
- 为了解决不同数据库同步的问题,DataX 把复杂的网状同步链条转成了星型数据链路,DataX 就是中间那个传输载体,连接各种数据源;
- 如果要接入一个新的数据源,直接把这个数据源接到 DataX 上,就能跟已有的数据源无缝同步了。
1. DataX 3.0 框架设计
DataX 使用的是 Framework + Plugin 架构,把数据源读取和写入的功能都抽象成了 Reader/Writer 插件,纳入整个同步框架。

| 角色 | 作用 |
|---|---|
| Reader(采集模块) | 负责采集数据源的数据,转交给 Framework。 |
| Writer(写入模块) | 从 Framework 中取数据,并写入目的端。 |
| Framework(中间商) | 连接 Reader 和 Writer,负责缓冲、流控、并发、数据转换等核心问题。 |
2. DataX 3.0 核心架构
DataX 做每个数据同步作业时,都会创建一个 Job。每当 DataX 收到一个 Job,它就会启动一个进程来完成同步任务。Job 模块是整个作业的中枢,负责数据清理、子任务切割、TaskGroup 管理等。
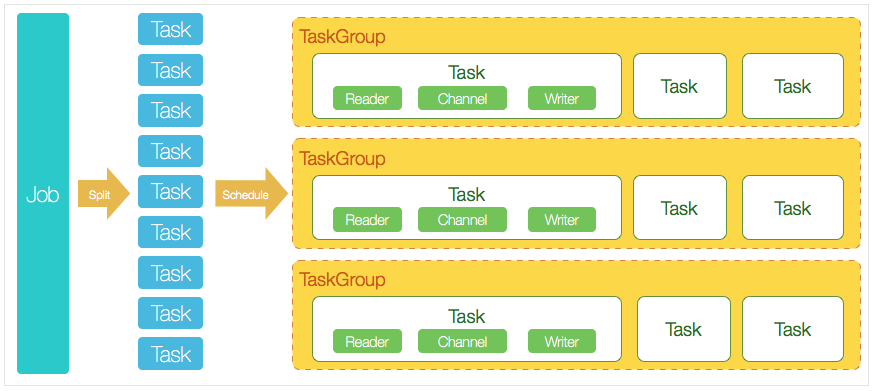
- DataX Job 启动后,会根据源端的切割策略把 Job 分成多个小 Task(子任务),便于并发执行。
- 接着,DataX 会调用 Scheduler 模块,根据配置好的并发数,把任务分配到 TaskGroup 中。
- 每个 Task 由 TaskGroup 负责启动,然后 Task 就会按照顺序启动 Reader → Channel → Writer 来完成任务。
- Job 启动后,会监控 TaskGroup,等所有 TaskGroup 完成后,Job 就算成功结束(如果异常退出,值为非 0)。
DataX 调度过程:
- 首先,Job 会根据分库分表策略,切割成若干个 Task,然后根据用户配置的并发数,计算需要多少个 TaskGroup;
- 计算方式:Task / Channel = TaskGroup,最后由 TaskGroup 根据并发数来执行 Task。
二、使用 DataX 实现数据同步
在开始之前,准备好以下环境:
- JDK(1.8 以上,推荐 1.8)
- Python(2 或 3 都行)
- Apache Maven 3.x(编译 DataX,tar 包方式不需要安装)

1. 安装 JDK
首先,下载并安装 JDK(需要先创建 Oracle 账号):
[root@MySQL-1 ~]# ls
anaconda-ks.cfg jdk-8u181-linux-x64.tar.gz
[root@MySQL-1 ~]# tar zxf jdk-8u181-linux-x64.tar.gz
[root@DataX ~]# ls
anaconda-ks.cfg jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[root@MySQL-1 ~]# mv jdk1.8.0_181 /usr/local/java
[root@MySQL-1 ~]# cat <<END >> /etc/profile
export JAVA_HOME=/usr/local/java
export PATH=$PATH:"$JAVA_HOME/bin"
END
[root@MySQL-1 ~]# source /etc/profile
[root@MySQL-1 ~]# java -version由于 CentOS 7 默认自带 Python 2.7,因此无需安装 Python。
2. 安装 DataX 软件
[root@MySQL-1 ~]# wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
[root@MySQL-1 ~]# tar zxf datax.tar.gz -C /usr/local/
[root@MySQL-1 ~]# rm -rf /usr/local/datax/plugin/*/._* # 删除隐藏文件(很重要)如果不删除隐藏文件,可能会出现错误信息:
[/usr/local/datax/plugin/reader/._drdsreader/plugin.json] 不存在,请检查您的配置文件。3. 验证安装
[root@MySQL-1 ~]# cd /usr/local/datax/bin
[root@MySQL-1 ~]# python datax.py ../job/job.json # 用来验证是否安装成功输出结果:
2021-12-13 19:26:28.828 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-13 19:26:28.829 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.060s | All Task WaitReaderTime 0.068s | Percentage 100.00%总结
使用 DataX 来进行数据同步,不仅提高了效率,还能确保数据的准确性。以上安装和配置过程就是在 Linux 环境下执行的,其他平台类似,只要配置好相关环境,DataX 就能顺利运行。