一、Java对象内存模型
Java对象在内存中由三部分组成:
 含类元数据指针(指向方法区的Class对象)和Mark Word(存储对象哈希码、锁状态、GC分代年龄等信息)。
含类元数据指针(指向方法区的Class对象)和Mark Word(存储对象哈希码、锁状态、GC分代年龄等信息)。
若为数组对象,还包含数组长度数据。
**1,**内存模型 -- Mark Word
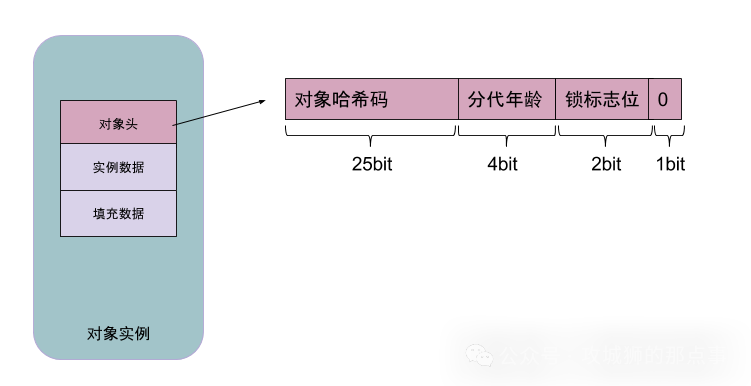
Mark Word是Java对象头(Object Header)的核心部分,用于存储对象运行时元数据,其结构随锁状态和GC阶段动态变化。以下是32/64位系统下的典型布局:
1),无锁状态(Normal)
| 位域 | 内容 |
|---|---|
| 25/29bit | 对象哈希码(hashCode) |
| 4bit | 对象分代年龄(GC年龄,最大15) |
| 1bit | 偏向锁标识(0表示未启用) |
| 2bit | 锁标志位(01) |
2),偏向锁(Biased)
| 位域 | 内容 |
|---|---|
| 23/54bit | 持有偏向锁的线程ID |
| 2bit | Epoch(用于批量重偏向) |
| 1bit | 偏向锁标识(1表示启用) |
| 2bit | 锁标志位(01) |
3),轻量级锁(Lightweight Lock)
| 位域 | 内容 |
|---|---|
| 30/62bit | 指向栈中锁记录的指针 |
| 2bit | 锁标志位(00) |
4),重量级锁(Heavyweight Lock)
| 位域 | 内容 |
|---|---|
| 30/62bit | 指向监视器(Monitor)的指针 |
| 2bit | 锁标志位(10) |
5),GC标记状态
| 位域 | 内容 |
|---|---|
| 30/62bit | 空(未使用) |
| 2bit | 锁标志位(11) |
关键设计原理
**1)****空间复用:**通过锁标志位(最后2bit)区分不同状态,同一存储区域在不同阶段复用2。
**2)****锁升级优化:**从无锁→偏向锁→轻量级锁→重量级锁逐步升级,减少同步开销35。
**3)GC协作:**分代年龄存储于Mark Word,配合可达性分析实现分代回收。
2,内存模型 -- Class Pointer
Class Pointer是Java对象头中的关键字段,用于指向方法区中该对象的类元数据(Class对象),其设计直接影响对象访问效率和内存占用。
核心作用
-
-
类元数据关联:存储对象所属类的类型信息(如方法表、字段表等)。
-
-
- 方法调用支持 :通过类指针定位虚方法表(vtable)实现动态绑定。
-
- GC与反射基础:为垃圾回收和反射操作提供类结构信息。
内存布局设计:
| 场景 | 指针大小 | 说明 |
|---|---|---|
| 64位系统(默认) | 4字节(压缩) | 启用 -XX:+UseCompressedClassPointers |
| 64位系统(关闭压缩) | 8字节 | 需显式配置 -XX:-UseCompressedClassPointers |
| 32位系统 | 4字节 | 无压缩选项,固定大小 |
访问方式对比:
**1)**句柄访问
使用句柄访问,会在堆中开辟一块内存空间作为句柄池,句柄中储存了对象实例数据(属性值结构体) 的内存地址,访问类型数据的内存地址(类信息,方法类型信息),对象实例数据一般也在heap中开辟,类型数据一般储存在方法区中。
| 优点 | 存储稳定的句柄地址,在对象被移动(gc) 时只会改变句柄中的实例数据指针,引用稳定 。 |
| 缺点 | 增加了一次指针定位的时间开销 。 |
2)直接指针访问:
直接指针访问方式指直接储存对象在heap中的内存地址,但对应的类型数据访问地址需要 在实例中存储。
| 优点 | 节省了一次指针定位的开销 |
| 缺点 | 对象移动需更新所有引用 |
3,内存模型 -- 指针压缩
1),压缩的目的:
为了保证CPU普通对象指针(oop)缓存
为了减少GC的发生,因为指针不压缩是8字节,这样在64位操作系统的堆上其他资源空间就少了。
2),压缩条件:
堆内存 ≤ 32GB(超过时压缩失效)。
默认开启,通过 -XX:+UseCompressedOops 同时压缩对象引用指针。
内存大于32G后,指针压缩失效是因为:
4G*8 = 32G。32位系统的CPU 最大支持2^32 = 4G。如果是64位系统,最大支持 2^64, 但是对其填充是按照8字节进行填充,指针压缩可以理解为在32位系统在64位上面使用,因为32位系统的CPU寻址空间最大支持4G,对其填充*8 = 32G,这就是内存>32G指针压缩失效的原因。 ####
关闭指针压缩:-XX:-UseCompressedOops
3,内存模型 -- 对齐填充
对齐填充的目的是,保证对象起始地址为8字节整数倍,提升内存访问效率。
内存对齐规则
- 32位系统默认4字节对齐,64位系统默认8字节对齐。
- 开启指针压缩(默认开启)时,对象头固定12字节,元数据指针由8字节压缩至4字节。
- 堆内存超过32GB时指针压缩失效,导致对象头膨胀。
二,JVM内存模型
- 内存模型 分为 私有区:进程计数器,虚拟机栈,本地方法栈。集线程共享区:堆和方 法区。 Java堆,是Java虚拟机管理的最大的一块内存,也是GC的主战场,里面存放的是几乎所有的对象实例和数组数据 。

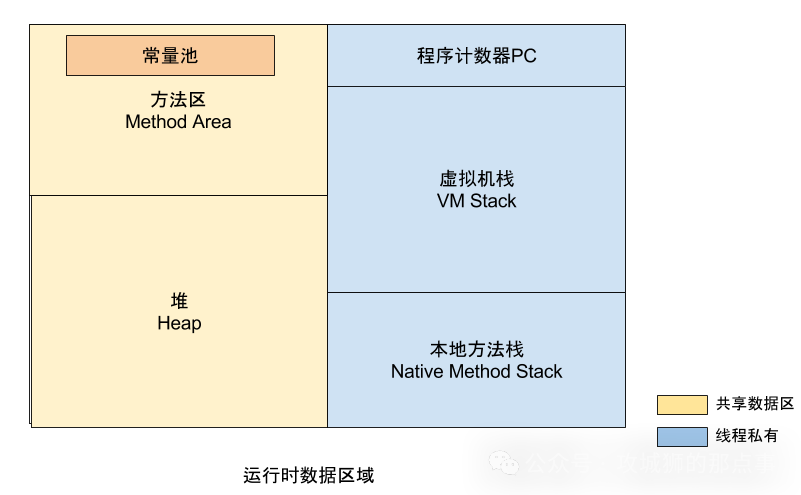
堆里面分为两个区域:新生代 和 老年代,新生代放新建的对象,当经过一定GC次数之后还存活的对象会放入老生代。新生代还有 3个区域:一个Eden +两个Survivor(S0/S1)。
垃圾回收的时候会将Eden中存活的对象放到一个未使用的Survivor中,并把当前的Endn和正在使用的 Survivor清除掉。
对象创建的过程是在堆上分配着实例对象,那么对象实例的具体结构如下:
对象的创建规则
- 对象优先分配在Eden区,如果Eden区没有足够的空间时,虚拟机执行一次Minor GC。
- 大对象直接进入老年代。这样做的目的是避免在Eden区和两个Survivor区之间发生大量的内存拷贝(新生代采用复制算法收集内存)。
- 长期存活的对象进入老年代。虚拟机为每个对象定义了一个年龄计数器,如果对象经过了1次Minor GC那么对象会进入Survivor区,之后每经过一次Minor GC那么对象的年龄加1,直到达到阀值对象进入老年区。
- 动态判断对象的年龄。如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代。
- 空间分配担保。每次进行Minor GC时,JVM会计算Survivor区移至老年区的对象的平均大小,如果这个值大于老年区的剩余值大小则进行一次Full GC,如果小于检查HandlePromotionFailure设置,如果true则只进行Monitor GC,如果false则进行Full GC。
三、对象死亡判定机制
1. 判定算法
1) 可达性分析(主流实现)
从 GC Roots 出发遍历引用链,未被链访问的对象标记为可回收GC Roots包括 :
-
线程栈中的局部变量
-
方法区中类静态变量
-
JNI引用的Native对象
-
系统类加载器加载的Class对 象
(2) 引用计数法(存在缺陷)
为对象维护引用计数器,引用增加时计数+1,失效时-1
无法解决循环引用问题(如对象A与B互相引用但无外部引用)
2. 判定流程
(1) 第一次标记
对象被判定不可达后,JVM标记为“待回收”并检查是否需要执行finalize()方法:
-
若对象未覆盖
finalize()或已执行过,则直接回收 -
若有必要执行,对象进入
F-Queue队列等待Finalizer线程触发
(2) 第二次标记
finalize()执行期间若对象重新建立与GC Roots的引用链(如将this赋值给全局变量),则移出回收队列
未逃脱的对象最终被回收
3. 引用类型对回收的影响
| 引用类型 | 回收条件 | 典型应用场景 |
|---|---|---|
| 强引用 | 引用链断开即回收 | 普通对象赋值 |
| 软引用 | 内存不足时强制回收 | 缓存实现(如图片缓存) |
| 弱引用 | 下次GC必定回收 | WeakHashMap等容器 |
| 虚引用 | 仅用于跟踪对象回收状态 | NIO DirectBuffer管理 |
注意:软/弱引用需配合ReferenceQueue使用,虚引用不能单独访问对象。
四、内存泄漏典型案例
场景示例:
java
Copy Code
// 循环引用导致无法回收(即使外部引用置空)
classNode {
Object data;
Node next;
}
Nodea=newNode();
Nodeb=newNode();
a.next = b;
b.next = a;
a = b = null; // 对象仍互相引用,但已不可达:ml-citation{ref="4" data="citationList"}
排查工具:
jmap -histo 查看对象数量异常增长
MAT分析堆转储文件定位引用链
通过内存模型与可达性分析机制的结合,可精准把控对象生命周期并优化内存管理策略。