redis集群简介
在redis单机模式下,所有的key都保存在同一个节点上,即便用了主从,主从服务器上也都保存了所有数据,难以支撑大数据量。引入集群模式后,可以把数据切分到集群内的多个节点,每个节点只保存一部分数据,单个节点依然可以配置主从来保障可用性,整体架构如下:
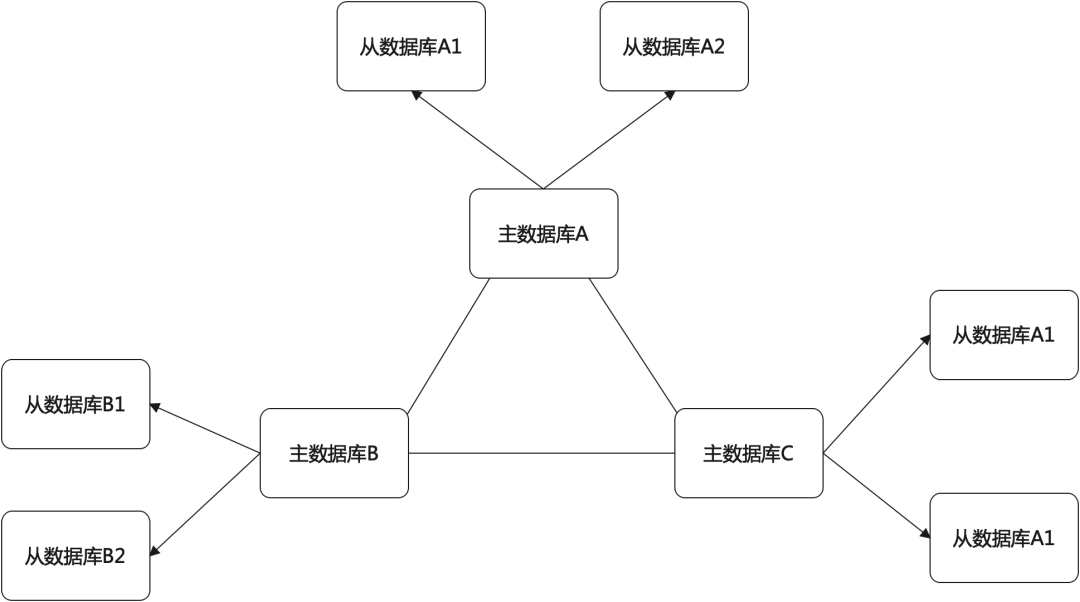
主数据库A、B、C组成了一个集群,对于每个主库,为保证高可用又分别配置了两个从库。
集群搭建
搭建步骤:
1、 启动集群中的所有Redis节点,注意开启cluster-enabledyes;
2、 通过clustermeet命令把节点逐个加入集群;
3、 通过clusterreplicate命令设置节点的主从关系;
4、 通过clusteraddslots命令给主库分配插槽;
看起来步骤有点多,没关系,别人都弄好了。使用redis-trib.rb可以快速完成集群搭建(需要安装Ruby)
$ /path/to/redis-trib.rb create --replicas 1 <IP:PORT> <IP:PORT> ...
--replicas 1表示每个主库拥有1个从库,该命令会自动计算出集群中需要分配几个主库、几个从库,并执行上述创建步骤。
插槽是什么
集群分片是以slot 插槽来分片的,一个集群中有16384个插槽,编号0-16383,插槽会平均分配到集群中的各个master节点,也可以在集群初始化之后进行动态调整。
key与slot的关系
key截取有效部分,使用CRC16算法计算出hash值,取16384的余数即为对应的slot。有效部分是指key中{}符号之间的部分,如果key不包含{}则整个key都是有效部分。
slot迁移
新插槽的分配比较简单,只需使用cluster addslots命令,而已分配插槽的迁移还涉及到数据的迁移,过程比较复杂,可以通过redis-trib.rb来完成。
# 使用reshard进行重新分片,这里只需提供集群任意节点的地址,脚本会自动获取集群信息
$ /path/to/redis-trib.rb reshard IP:PORT
# 接下来是一段交互式操作,先询问迁移多少个插槽
How many slots do you want to move (from 1 to 16384)
# 询问迁移到哪个节点,这里需要输入节点的运行ID
What is the receiving node ID
# 接着要输入迁出插槽的节点,根据提示操作
Please enter all the source node IDs.
# 还需要确认分片方案,通过yes来确认
通过rb脚本进行迁移需要交互式操作,不适用于自动化场景,这里同时介绍迁移过程用到的命令,必要时可以自己实现迁移过程。假设现在需要把0号插槽从A迁移到B
1、 在B节点执行clustersetslot0importingA,设置状态为正在迁入;
2、 在A节点执行clustersetslot0migratingB,设置状态为正在迁出;
3、 使用clustergetkeysinslot0命令查询插槽0对应的key;
4、 对于每一个key,都要使用migrate命令将其迁移到目标节点B,不使用COPY模式;
5、 全部key迁移完成后,使用clustersetslot0nodeB迁移插槽,A和B的迁移状态被清除;
这里重点关注在迁移过程中的key是如何访问的?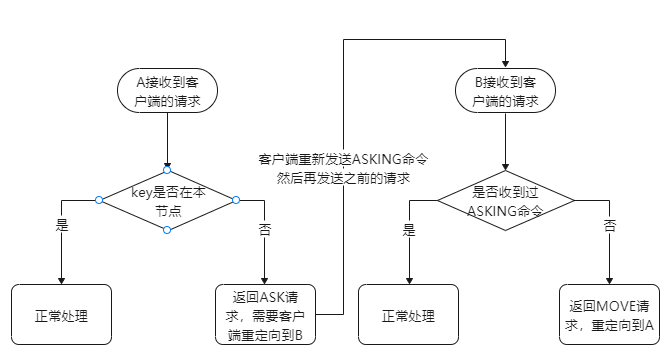 上面说迁移过程不是用COPY模式,也是为了保证只有一个节点存在同一个key,否则A节点迁移完某个key后,后续又来一个请求需要删除这个key,整个迁移全部完成后,在B节点仍存在原本需要被删除的key,会存在数据不一致
上面说迁移过程不是用COPY模式,也是为了保证只有一个节点存在同一个key,否则A节点迁移完某个key后,后续又来一个请求需要删除这个key,整个迁移全部完成后,在B节点仍存在原本需要被删除的key,会存在数据不一致
对集群的数据访问
当redis启用集群模式后,key通过分片散落在集群内,因此在集群模式下的数据访问过程与单机模式稍有不同。
当客户端向集群中的任意节点发送命令后
1、 节点收到命令,判断相应的key是否在当前节点中,如果在当前节点就正常处理命令;
2、 如果key不在当前节点,就会返回一个MOVE重定向请求,类似于(error)MOVEDslot_idip:port;
3、 客户端收到MOVE重定向请求,需要重新向key所在的节点再次发送命令;
并不是所有客户端都支持命令重定向,若不支持则需要应用层来实现,注意如果发生重定向则需要向两个Redis节点发送两个命令才能完成操作,对性能会产生影响,因此客户端应该做必要的缓存来提升性能。如果key较少可以缓存key与节点的映射关系,key较多则可以缓存slot与节点的映射关系,slot数量只有16384个,需要客户端通过key计算对应的slot。
高可用
在默认情况下,只要有一个插槽所在的主从库都下线,整个集群都会进入下线状态,通过配置cluster-require-full-coverage为no来避免这种情况。更常见的做法是,为每一个主库至少配置一个从库以避免单点故障。
故障恢复机制
在集群中,每个节点每1秒钟向其他节点发送PING命令,通过回复来判断目标节点状态。
1、 如果在一定时间内未收到回复,则发起PING命令的节点会认为目标节点疑似下线PFAIL,类似于哨兵的主观下线;
2、 一旦A节点认为B节点疑似下线,就会在集群中传播该消息,其他节点会记录这一信息;
3、 同样其他节点也会认为B节点疑似下线并向A发送消息,当A节点收到半数以上的节点认为B疑似下线时,就会将B标记为下线FAIL,并再向其他节点传播该消息,最终使B在集群中下线;
当一个主库下线后,就会出现一部分插槽无法写入,这时候就要选择一个从库转变成主库。选举过程基于Raft算法,当某个从库当选为主库后,通过slaveof no one命令将自己转换为主库,并将旧主库的插槽转换给自己负责。