你的第一个 Spring AI 1.0 应用
作者:Mark Pollack 博士、Christian Tsolov、Josh Long
嗨,Spring 的铁粉们!Spring AI 已经 上线,现在你可以在 Spring Initializr 上直接使用它,哪里有高级字节,哪里就有它的身影。先问一句:你准备好把 AI 引入项目了吗?现在是 Java 和 Spring 开发者最美好的时代。特别是在这波 AI 热潮中,Spring 开发者有天然优势。
说到底,所谓 AI 工程,90% 都是和模型打交道,而这些模型几乎都通过 HTTP API 提供服务——输入是人类语言的字符串(String),这不就是咱们 Spring 应用最擅长处理的集成场景吗?让 AI 模型自然地接入到 Spring 的业务流程里,是最顺手不过的事儿。
AI 工程的痛点与设计模式
AI 很强大,但不是全能的,它也有不少坑。搞 Spring AI 的时候,你得有几个常识和模式打底,走得更稳:
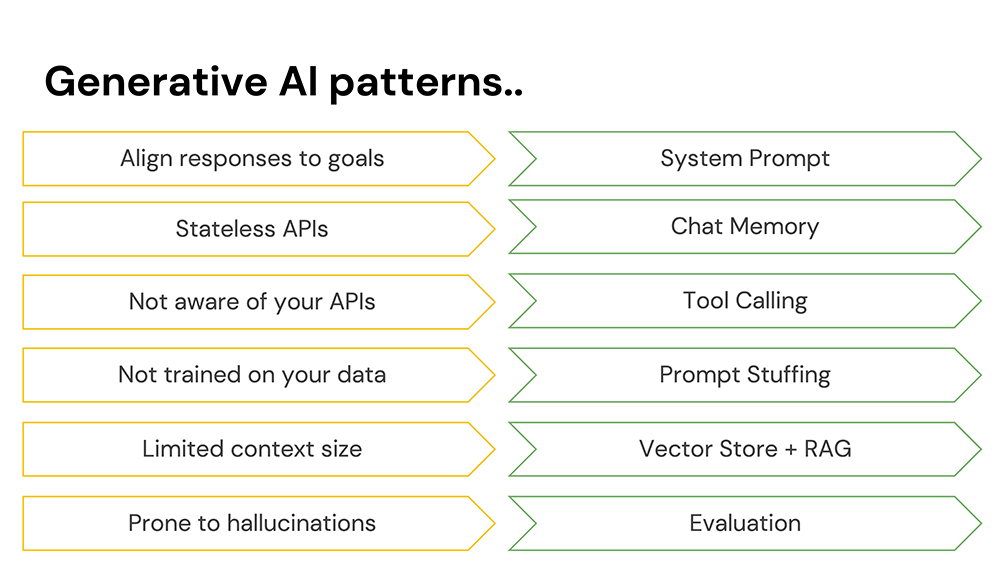
- 模型像个话唠,啥都愿意聊。要让它专注,得下个“系统提示(system prompt)”来定调。
- 模型其实是无状态的。你之所以觉得它能“记得你说过什么”,是因为每次请求都会带上对话记录,也就是“聊天记忆(chat memory)”。
- 模型运行在一个沙箱里。这很合理——毕竟大家都看过《终结者》嘛。不过,如果你允许它调用一些“工具方法(tool calling)”,它确实能干不少事。
- 模型虽聪明,但也不是全知的。你可以通过请求体传入一些上下文信息来“填充提示(prompt stuffing)”。
- 但别塞太多数据!用 向量存储(vector store) 选出相关信息,然后用 RAG(检索增强生成) 技术送给模型分析,才是正解。
- 聊天模型爱乱说,也就是“幻觉(hallucinations)”。所以要用 评估器(evaluators) 来验证它说的靠不靠谱。
对 Spring 开发者而言的小步,对 AI 世界来说的大跃进
Spring AI 是 AI 工程的大跃进,但对咱 Springer 来说,那感觉就像“又一个 Starter 包”。它支持多个模型后端、统一的服务抽象、开箱即用的 Boot 自动配置,还支持虚拟线程、GraalVM 原生镜像、Micrometer 可观测性……
开发体验也丝滑——集成 Spring Devtools,支持 Docker Compose 和 Testcontainers。你可以像启动任何 Spring 项目一样,直接从 Spring Initializr 开整。
项目案例:狗狗收养助手
咱不光是聊概念,咱要撸个实打实的案例——做个“领养狗狗”的 AI 助手!灵感来自 2021 年在网上爆红的一只狗——Prancer,这货性格那叫一个“社会人”,看这个领养广告的原文节选:
我尽力了,这几个月一直想给这只狗写个看上去能领养的广告,但他就是不行。你要是找一只神经质、讨厌男人、讨厌动物、讨厌小孩、长得像个小妖精的狗,那这就是你梦中情狗了。可我家人实在扛不住了,每天活在这只恶魔吉娃娃制造的地狱里。
行吧,有个性狗狗也值得一个家。咱就整一套服务,帮人找到梦中情狗(或噩梦情狗?)。
前置准备工作
听着是不是挺折腾?但再咋“炸裂”的狗也值得一个家。咱现在就来搭个服务平台,撮合人和狗的“世纪大联姻”。
打开 Spring Initializr 网站,创建项目时,勾上这些依赖:
PgVectorGraalVM Native SupportActuatorData JDBCJDBC Chat MemoryPostgresMLDevtoolsWeb
选择 Java 24 或更新版本,构建工具用 Apache Maven(当然你想用 Gradle 也没毛病,只是本文例子用 Maven 来写的)。项目的 artifactId 起名叫:adoptions。
你的 pom.xml 里,记得也要加上这个依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
下面是这些依赖各自的职责:
Data JDBC:Spring Data JDBC ORM 映射工具,简化和 SQL 数据库的交互。Web:就是老熟人 Spring MVC。Actuator:提供应用健康检查、指标监控,背后是 Micrometer。Devtools:开发时用,支持热部署(比如你在 VS Code / Eclipse 保存就自动重启;IntelliJ IDEA 切个 tab 就触发重启)。GraalVM Native Support:支持构建 GraalVM 原生镜像(轻量+启动快,爽得很)。
说白了,这些就是让你写得快、跑得稳、还能部署到生产里的全家桶。
数据库配置
咱说了要用 SQL 数据库,那用啥?当然是老伙计 PostgreSQL 啦!不过这次我们不光用普通的 Postgres,还得整两个插件:vector 和 postgresml。
vector插件让 PostgreSQL 能当 向量数据库 来用。postgresml插件内置了一个 embedding 模型,可以把文字、图片啥的转成向量。
Spring AI 里,选用哪个向量存储、embedding 模型、聊天模型,这三样是核心搭配。
本例中咱用的聊天模型是 Claude。你需要去 Anthropic 官网 注册个开发者账号,搞到 API Key 才能用。Claude 是个脾气好的模型,稳健、保守、不会乱说话,很适合企业场景。
启动 PostgreSQL 服务
我已经准备好了一个带插件的 Docker 镜像,路径在项目里的 adoptions/db/run.sh,你只要运行它就能起服务:
bash adoptions/db/run.sh
然后初始化数据库用户(建库 + 用户权限等):
bash adoptions/db/init.sh
完事之后,配置数据库连接,在 application.properties 里加上这些内容:
spring.sql.init.mode=always
spring.datasource.url=jdbc:postgresql://localhost:5433/postgresml
spring.datasource.username=myappuser
spring.datasource.password=mypassword
spring.ai.postgresml.embedding.create-extension=true
spring.ai.postgresml.embedding.options.vector-type=pg_vector
spring.ai.vectorstore.pgvector.dimensions=768
spring.ai.vectorstore.pgvector.initialize-schema=true
spring.ai.chat.memory.repository.jdbc.initialize-schema=always
解释一下:
- 告诉 Spring Boot 每次启动都执行初始化 SQL。
- 启用 PostgresML 的
pgvector向量类型。 - 配置向量维度是 768(这跟你选用的 embedding 模型有关)。
- 自动建表建 schema(向量表 + 聊天记录表都一键起飞)。
加载数据:导入狗狗信息
我们需要把狗狗的信息(名字、描述、主人等)灌进数据库里,配合 schema.sql 和 data.sql。
然后,为了方便操作数据,我们加一个 Spring Data JDBC 的实体类 + 仓库,贴到 AdoptionsApplication.java 结尾:
interface DogRepository extends ListCrudRepository<Dog, Integer> {
}
record Dog(@Id int id, String name, String owner, String description) {
}
就这么简单,Spring 会自动给你实现增删查。
聊天助理上线啦
我们要让用户通过 HTTP 访问 AI 助手。来,撸个控制器类:
@Controller
@ResponseBody
class AdoptionsController {
private final ChatClient ai;
AdoptionsController(ChatClient.Builder ai) {
this.ai = ai.build();
}
@GetMapping("/{user}/assistant")
String inquire(@PathVariable String user, @RequestParam String question) {
return ai
.prompt()
.user(question)
.call()
.content();
}
}
然后你就可以用命令访问它啦,比如:
http :8080/jlong/assistant question=="my name is Josh"
Claude 会给你一个“老朋友久违”的热情回复,挺会聊天。
聊天记忆:Claude 忘性有点大?
我们试试下面这个:
http :8080/jlong/assistant question=="what's my name?"
结果你会发现 Claude 根本记不得你叫啥——那咋办?
咱得给它整点记忆力。这就得用 Spring AI 提供的一个拦截器,叫:PromptChatMemoryAdvisor,可以自动存储上下文。
加到你的主类里(AdoptionsApplication.java):
@Bean
PromptChatMemoryAdvisor promptChatMemoryAdvisor(DataSource dataSource) {
var jdbc = JdbcChatMemoryRepository.builder().dataSource(dataSource).build();
var chatMemory = MessageWindowChatMemory.builder().chatMemoryRepository(jdbc).build();
return PromptChatMemoryAdvisor.builder(chatMemory).build();
}
你可以把这玩意当成 AOP 里的 “切面” 理解 —— 请求发出前给它塞点信息,请求回来后把对话记下来。
这玩意自动把聊天信息存在 PostgreSQL 里,我们前面不是配置过自动建表了吗?完美对接!
聊天记忆集成进控制器
改一下 Controller 构造函数,让它支持这个记忆插件:
AdoptionsController(PromptChatMemoryAdvisor promptChatMemoryAdvisor, ChatClient.Builder ai) {
this.ai = ai
.defaultAdvisors(promptChatMemoryAdvisor)
.build();
}
还得在请求里告诉模型:“这段话是谁说的”,我们用 URL 里的 user 字段作为会话 ID:
@GetMapping("/{user}/assistant")
String inquire(@PathVariable String user, @RequestParam String question) {
return ai
.prompt()
.user(question)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, user)) // 这句关键!
.call()
.content();
}
现在你重启程序,再问一遍:
http :8080/jlong/assistant question=="my name is Josh"
http :8080/jlong/assistant question=="what's my name?"
Claude 就该记住你了!如果不想让它记住?删掉那张表的数据就行了。
系统提示:别让 AI 胡说八道
目前这个 AI 助手啥都聊,那你可真成了“Claude 桌面端”。可咱的目标不是做个万能 AI,而是要打造一个帮人“领养狗狗”的 AI 助手。
给它一个“工作指令”吧,也就是传说中的 “System Prompt”:
var system = """
你是一个由 Pooch Palace 狗狗领养机构提供的 AI 助理,机构在里约热内卢、墨西哥城、首尔、东京、新加坡、纽约、阿姆斯特丹、巴黎、孟买、新德里、巴塞罗那、伦敦和旧金山设有据点。以下是待领养狗狗的信息。如果没有数据,请礼貌地告诉用户我们目前暂无狗狗可领养。
""";
this.ai = ai
.defaultSystem(system)
.defaultAdvisors(...)
.build();
再来问:
http :8080/jlong/assistant question=="do you have any neurotic dogs?"
现在它就会尝试根据咱的数据库找答案,不再跑题讲 Java 了。
别把 Token 花光:加点可观测性
你现在是不是想说:“那我直接把整张狗狗表的数据读出来,拼接到请求体里不就行了?”
嗯,理论上行。但别忘了:每次调用大模型都会消耗 token,不是钱就是算力,成本可不低。
为了省 token,你应该学会“按需传数据”。
咱可以通过 Spring Boot Actuator 来监控 token 的使用情况,方法如下:
第一步:开启监控端点
在 application.properties 里加上:
management.endpoints.web.exposure.include=*
management.endpoint.health.show-details=always
第二步:查看指标数据
重启应用后,访问:
http://localhost:8080/actuator/metrics
你会看到很多指标,重点关注这个:
gen_ai.client.token.usage
访问:
http://localhost:8080/actuator/metrics/gen_ai.client.token.usage
就能看到每次和 Claude 聊天到底用了多少 token。Micrometer 项目支持把这些指标上报到各种 TSDB(Prometheus、Grafana、DataDog、Dynatrace 等),方便你做可视化运维面板。
使用向量检索(RAG):只喂 AI 需要的内容
既然数据都在 PostgreSQL 里了,我们要做的事是:
- 把狗狗数据变成
Document类型,塞进向量数据库; - 每次请求时,从向量数据库中检索相关内容再给 AI 模型分析;
- 这就叫:RAG(Retrieval Augmented Generation)。
来,改造一下 Controller 构造函数,把狗狗数据导入向量存储:
AdoptionsController(JdbcClient db,
PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai,
DogRepository repository,
VectorStore vectorStore) {
var count = db.sql("select count(*) from vector_store")
.query(Integer.class)
.single();
if (count == 0) {
repository.findAll().forEach(dog -> {
var doc = new Document(
"id: %s, name: %s, description: %s".formatted(
dog.id(), dog.name(), dog.description()
)
);
vectorStore.add(List.of(doc));
});
}
this.ai = ai
.defaultAdvisors(promptChatMemoryAdvisor,
new QuestionAnswerAdvisor(vectorStore))
.build();
}
意思就是:项目第一次启动时,把所有狗狗信息转换成 Document,塞进向量数据库(由 PostgresML 支持)。
再来看 QuestionAnswerAdvisor —— 它的作用是:
在用户提问后,自动到
vectorStore里找相关内容,送给 Claude 作为提示。
然后你再问:
http :8080/jlong/assistant question=="do you have any neurotic dogs?"
Claude 这回就能查到 Prancer 了(之前不是说这家伙“性格火爆”吗),顺利返回一条真实靠谱的答案!
Structured Output:不光会说,还要能“说人话”
目前为止,我们从 Claude 那边拿到的都是字符串文本,但如果你想搞个强类型 Java 对象咋整?
来,假设我们有个结构体叫:
record DogAdoptionSuggestion(int id, String name, String description) {}
你可以像下面这样调用:
@GetMapping("/{user}/assistant")
DogAdoptionSuggestion inquire(...) {
return ai
.prompt()
.user(...) // 你的问题
.entity(DogAdoptionSuggestion.class); // 自动解析成对象
}
Claude 会根据你给它的 Prompt,自动生成 JSON 并映射到这个结构上,免得你再自己手动 Jackson.parse()。
当然我们本教程还是继续用 .content() 返回文本就好,毕竟我们做的是聊天机器人嘛。
Local Tool Calling:让 AI 自动“约领养时间”
现在用户已经知道哪只狗合适了——那自然要下一步:预约、领养!
咱就整一个“预约调度器”,并暴露成可以被 Claude 调用的工具。
加个 Bean 到你的项目中:
@Component
class DogAdoptionScheduler {
@Tool(description = "schedule an appointment to pickup or adopt a dog from a Pooch Palace location")
String schedule(int dogId, String dogName) {
System.out.println("Scheduling adoption for dog " + dogName);
return Instant.now().plus(3, ChronoUnit.DAYS).toString();
}
}
这类 @Tool 注解,就是告诉 Spring AI —— 这方法是可以被大模型调的“工具”。你得写明白这个方法是干啥的,用人类话说清楚,这样 Claude 才懂怎么用它。
小贴士:你小时候妈不是常说“你倒是说话啊”?这时候你妈的训话特别适用,工具描述一定要写得“清清楚楚”。
工具注册到 ChatClient
还得把这个 DogAdoptionScheduler 注册进 AI 里:
AdoptionsController(JdbcClient db,
DogAdoptionScheduler scheduler,
ChatClient.Builder ai,
DogRepository repository,
VectorStore vectorStore) {
// ...
this.ai = ai
.defaultTools(scheduler) // 注册工具
.defaultAdvisors(...)
.build();
}
现在来试试看咱的“全流程”:
- 问 Claude 有没有神经质的狗(Prancer 会出现):
http :8080/jlong/assistant question=="do you have any neurotic dogs?"
- 然后问:我想从 NYC 的门店约领养:
http :8080/jlong/assistant question=="fantastic. when can i schedule an appointment to pickup Prancer from the New York City location?"
Claude 会调用你暴露的 schedule() 方法,控制台就会输出预约信息,并返回一个 3 天后的预约时间。成了!
什么是 MCP(Model Context Protocol)?##
Claude 的 MCP(模型上下文协议)是个新玩意,用来让模型通过统一协议访问“外部工具”。2025 年 11 月 Claude Desktop 推出 MCP 支持,瞬间成了爆款。
它有两种模式:
- STDIO 模式:本地服务通过标准输入输出与模型通信;
- HTTP SSE 模式:远程服务通过 Server-Sent Events 和 Claude 通信。
MCP 的爆炸式增长堪比“工具类创业潮”,现在:
- 有 Spring Batch 的 MCP 服务、
- 有 GitHub 的 MCP 服务、
- 有 Google Cloud、AWS、Heroku、Office、Adobe 的 MCP 服务、
- 甚至连渲染 Blender 3D 场景都能整成 MCP!
你要干嘛它都有人写好了服务,Claude 也就越来越聪明了。
把我们的“预约服务”提取为独立 MCP 服务
现在咱就把 DogAdoptionScheduler 单独拆出来,变成远程 MCP 服务,Claude 通过 HTTP 来调用。
第一步:新建 scheduler 项目
- 添加依赖:
GraalVM Native Support、Web、Model Context Protocol Server - Java 版本选 24+
- 构建工具选 Maven
- 项目名填:
scheduler - 点击生成 ZIP,解压后导入 IDE
第二步:迁移预约类
把之前的 DogAdoptionScheduler 类 copy 到新项目里。然后在主类 SchedulerApplication.java 中注册 MCP:
@Bean
MethodToolCallbackProvider methodToolCallbackProvider(DogAdoptionScheduler scheduler) {
return MethodToolCallbackProvider.builder().toolObjects(scheduler).build();
}
第三步:换个端口
别跟主项目端口冲突,application.properties 中设置:
server.port=8081
修改原项目,指向远程 MCP
回到 adoptions 项目,把所有关于 DogAdoptionScheduler 的代码删除掉。我们要改用远程工具。
添加配置:
@Bean
McpSyncClient mcpSyncClient() {
var mcp = McpClient
.sync(HttpClientSseClientTransport.builder("http://localhost:8081").build())
.build();
mcp.initialize();
return mcp;
}
在 Controller 构造函数中改为:
this.ai = ai
.defaultToolCallbacks(new SyncMcpToolCallbackProvider(mcpSyncClient))
.build();
搞定!现在 Claude 调用的是一个真正“远程可部署”的工具服务!
测试远程 MCP 服务
重新启动 scheduler 项目和 adoptions 项目,再来一套:
http :8080/jlong/assistant question=="do you have any neurotic dogs?"
http :8080/jlong/assistant question=="when can i schedule an appointment to pickup Prancer from the New York City location?"
你会在 scheduler 项目的控制台里看到调度输出,说明 Claude 真的通过 MCP 成功调用你的 HTTP 工具服务啦!
Claude Desktop × MCP:配置远程集成
Claude Desktop 支持加载本地 .json MCP 配置文件,例如 GitHub 工具服务的配置:
{
"mcpServers": {
"github": {
"command": "docker",
"args": [
"run", "-i", "--rm", "-e", "GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "..."
}
}
}
}
Spring AI 也兼容这个配置格式,你只要把 .json 配置路径告诉它:
spring.ai.mcp.client.stdio.servers-configuration=classpath:/github-mcp.json
之后 Claude 就可以帮你发起调度,还能写入 GitHub issue、发起 PR…… 全自动!
上生产之前,要搞这些
安全性(Security)
Spring Security 是你最靠谱的朋友,想给系统加权限、搞登录、甚至对 AI 聊天内容加密都很方便。
比如之前我们用的是 user path variable 作为聊天会话 ID,实际上你可以改成这样更安全:
Principal principal // 控制器参数注入
principal.getName() // 获取当前用户 ID 作为会话ID
数据库层面,聊天记录这些东西可能比较敏感,可以启用 数据库静态加密(encryption at rest)来保护数据。
可扩展性(Scalability)
AI 服务性能消耗大,尤其是模型交互、数据库查询这些都是阻塞型 IO,线程就傻等着,太浪费了!
Java 21 给咱带来救星:虚拟线程(Virtual Threads)!
你只要在配置里加一句:
spring.threads.virtual.enabled=true
你就能把每一个用户请求扔进一个轻量虚拟线程里,吞吐量直接起飞!
原生镜像(GraalVM Native Image)
GraalVM 就是你手里的“终极奥义”了,它把 JVM 项目 AOT 编译成操作系统级别的超轻量二进制程序。
步骤一:安装 GraalVM(用 SDKMAN 管理)
sdk install java 24-graalce # 社区版
sdk install java 24-graal # Oracle 版
sdk use java 24-graal
步骤二:打包编译
./mvnw -DskipTests -Pnative native:compile
这个编译过程有点长,建议泡杯咖啡等会。编译完成后你会看到一个可执行文件,比如:
./target/scheduler
启动速度嗖嗖的,日志打印的 PID 拿去一查内存:
ps -o rss <PID>
单位是 KB,除个 1000 就是 MB —— 少得让你想哭,JVM 完全打不过原生程序。
Docker 构建镜像
还想部署到云平台?那就得给它装进 Docker 镜像里!
./mvnw -DskipTests -Pnative spring-boot:build-image
等待片刻后,你会看到构建好的 Docker 镜像名字,运行它的时候记得映射端口和配置文件。
顺便一提:我在 macOS 的虚拟机上测了下这个镜像,跑得比宿主机还快,真离谱!
可观测性 + 成本监控
这套应用上线之后,说不定能像 Prancer 一样上热搜。为了别被打爆,你得监控它的运行状态,尤其是:
- 系统资源:CPU、内存、线程
- Token 消耗:每个请求用了多少 token(成本)
- 错误率:模型输出不靠谱的频率
前面我们已经通过 Spring Boot Actuator + Micrometer 整好了指标采集接口,现在你可以把数据上报到:
- Prometheus + Grafana(自托管)
- DataDog、Dynatrace(云监控)
- ElasticSearch + Kibana
- 甚至飞书/钉钉/企业微信报警
所有 LLM 都有“成本”,你得盯紧了,不然月底账单把你吓秃!
下一步?
恭喜你,铁子!
你刚刚撸完了一套可上生产的 AI 聊天服务系统:
- Claude 聊天 + 向量检索(RAG)
- Spring Data + Postgres + pgvector + PostgresML
- Chat Memory 记忆力管理
- Tool Calling 工具方法调用
- MCP 远程工具服务对接
- GraalVM 编译 + Docker 镜像
- 监控可观测性一条龙
这玩意现在去搞个 AI 领养狗平台、AI 文档助手、AI 题库问答、AI 面试神器…… 随便改个主题都能变现!