抱着学习的目的仔细看了分享,记录一些笔记且总结出来了实践过程中的精华部分,仅供参考。
背景
我们先分析一下小红书的一些业务背景。
小红书是典型UGC内容平台,很多公司都有类似的业务场景。从业务背景上,小红书当前的主要业务场景是处理用户行为日志(如浏览、点赞、收藏),覆盖推荐、搜索、电商等核心场景,数据增量日军千亿级别。
算法需要进行分钟级的调参,并且实验指标需要进行全量计算,且要求实时和离线指标实现最终一致(差异<1%)。
所以从背景和需求上来看,当前业务场景核心的业务诉求有两个:
1、 时效性,要求分钟级;
2、 全量计算,且保证数据准确。
当前遇到的问题
在采用湖仓和增量计算前,小红书也是采用了经典的Lamda架构,也就是离线和实时两条链路。在这个过程中遇到了非常经典的问题:
1. 成本很高
Flink任务作为常驻任务,消耗超过5000core,且因为超大数据量导致状态很大(如大开窗聚合),内存压力很大,并且资源成本随流量增长线性上升。
这是经典的Flink处理超大流量数据,并且需要状态计算带来的问题,资源消耗是一方面,另外一方面就是稳定性问题。
2. 两条链路带来的高复杂度
Lamda架构的痛点之一,实时链路(Flink+Redis+ClickHouse)与离线链路(Spark+Hive)逻辑割裂,维表更新、指标计算一致性难以保障。
并且在这个过程中因为需要通过维度表拓维,实时链路依赖的 KV 存储成为瓶颈。
3. 开发成本和风险高
超大数据规模下的大窗口(如7天),状态膨胀严重,所以需要缩小时间窗口,但是带来的数据质量问题。
并且因为实验指标频繁变更,schema变更导致任务开发迭代周期较长。
解决方案和技术细节
最终采用的方案是:
- Iceberg+Paimon实现数据存储和消费
- Spark分钟级调度产出分钟级汇总数据
- StarRocks读取湖数据实现加速查询
架构图来自官方分享:
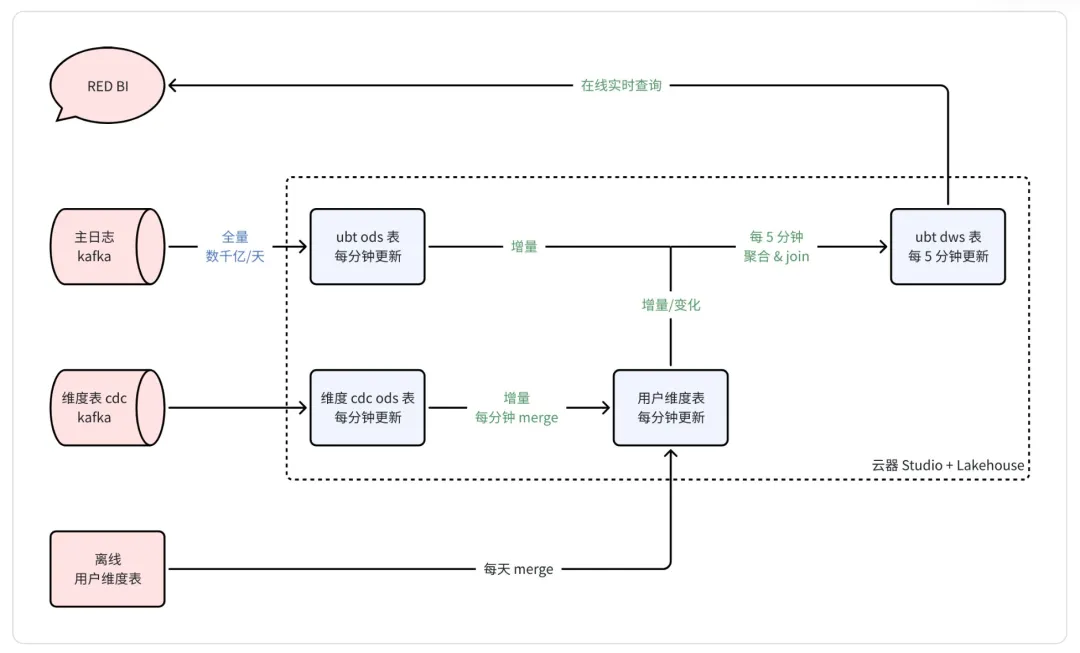
我们稍微展开详细分析:
关于湖框架的技术选型,这里小红书选择了Iceberg作为基座,Paimon作为维度表,当然因为不同公司的技术栈不同,用户可以灵活选择自己公司当前在用的框架。Iceberg采用append only模式写入数据,同时提供给离线和实时两条链路使用(因为下游是Spark的分钟级调度,其实只有准实时这一条链路了);
同时利用Paimon强大的维度表能力,选择Paimon作为维度表存储,减少对KV存储的依赖。
其次,利用StarRocks作为查询引擎,直接查询结果数据进行聚合,这也是我们在数据开发上经常用到的使用StarPocks、Doris等直接读取离线数据进行加速查询的场景。
技术细节上:
1、 分钟级的DWS设计
在模型设计层面,设计了<分钟,user_id> 粒度的数据,把明细日志转化成了5分钟+用户粒度的DWS层数据,同时在分钟级调度任务中关联用户维表,整体数据规模大幅度缩小。
2、 实时维度表
用户实时Kafka数据对维度表进行分钟级更新;天级更新的维度,通过离线调度写入。通过判断表中的时间戳,实现按需更新。
3、 Shema设计
每当有指标增减,会涉及宽表的schema evolution,会导致上下游表结构的订正。采用JSON结构存储算法指标,实现用户在JSON列中自助增减指标,提升开发效率。
4、 维度表设计
当前这个场景,通过UDF中更新用户实验维度表。并且设计了用户实验维表的格式为<user_id,exp_ids>,exp_ids的数据结构为array,并且对exp_ids建立倒排索引,查询效率大幅提升。
收益
最终增量计算+实时湖仓的方式,当前场景下效果显著:
1、 时效和数据质量上
在满足业务需求的前提下,时效变为分钟级,并且可以动态调整计算周期,平衡不同场景下的时效性与资源消耗。
链路上从原来Lambda两条链路演变成湖仓一条链路,数据差异大幅降低至<1%。
2、 计算和迭代成本上
近实时链路资源消耗上降低明显(为原来的36%),预聚合的方式将数据量从数千亿条日志压缩至数亿条,存储成本同比下降约90%。
此外采用JSON半结构化建模,不需要修改表结构,开发效率提升50%+。
3、 查询性能上
通过分钟级DWS层(5分钟+用户粒度聚合),将明细查询转换为聚合结果查询,查询P90延迟从分钟级优化至<10秒。
以上就是本次学习和分享的内容,希望对大家有帮助。